自宅で簡単☆計算加速装置
この記事は UEC Advent Calender2020 10日目の記事です。前日の記事はSuzukeさんのクソコラ拡張機能の作り方でしたね。
アクセラレータと聞いて白髪のロリコンが最初に思い浮かぶオタクのみなさん、作りましょう。
本記事では何か適当なアクセラレータを自作し、某ラノベを読んで拗らせたオタクに「俺はアクセラレータ自作したけど、お前は?」と煽り散らす事を目的としています。
下調べ
まずは世の中にはどんなアクセラレータが存在するのか見てみましょう。
Coral USB Accelerator
www.switch-science.com Coral社が販売しているAIアクセラレータ、googleのEdge TPUが乗っています。 Type-Cで接続するだけで推論が加速する!嬉しい!
Nural Compute Stick 2
www.switch-science.com intelが販売しているDNN用アクセラレータ、見た目がすき。
K210
www.switch-science.com 正確にはアクセラレータではない、RISC-VデュアルコアでセキュリティやAI、音声認識向けのアクセラレータがもりもり乗ったSoC。お化け。
要はアクセラレータとはオンチップ or 外付けで特定の計算が爆速になる不思議な半導体のことを指しているわけです。今回は行列計算関係のアクセラレータを作りましょう。流行ってるので。
コア技術
如何にしてCPUの逐次処理より高効率に行列計算を行うか?答えはシストリックアレイです。シストリックアレイとは単純な処理を行うPE(Processing Element)と呼ばれる演算器を直線状、格子状、ツリー状等に並べることで、高い並列性で特定の演算(高速フーリエ変換、ソート、行列演算 etc..)を実行できるアーキテクチャを指しています。
今回用いるPEは左と上のポートから来た値を乗算し、バッファに加算、また右の値を左のポートに出力する単純な処理を行います。
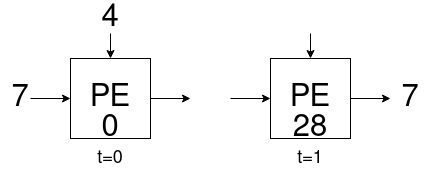
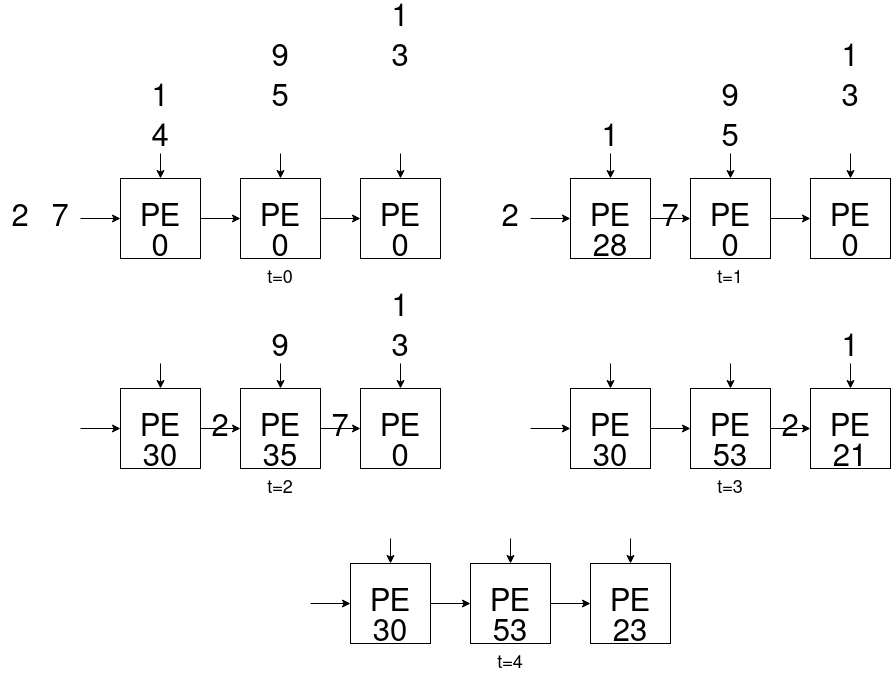
このPEを線形に並べることで行列-ベクトル積を実行できるシストリックアレイが完成します。
for(int i = 0; i < N; i++){ for(int j = 0; j < N; i++){ C[i] += A[i][j]*B[j]; } }
の通りO(N2)ですが、シストリックアレイを用いると行列サイズNに対して2N-1ステップで計算が完了するため効率的です。本記事ではこのシストリックアレイをコアに据え、行列-ベクトル積のアクセラレータを作成します。
悲しみ
行列-ベクトル積のアクセラレータを作成します。と意気込んだものの障害は多いです。
1. CPU-アクセラレータ間の通信
アクセラレータとCPUでデータを受送信する上でDMAを使えたら嬉しいですね(早いので)?DMAが使えるFPGAの値段を見てみましょう!
www.intel.co.jp 12万円 www.avnet.com 20万円 www.digikey.jp 32万円
これは草。学生風情が趣味で買うものでは無いのは明らかです。Zynq?知らない子ですね。つまり我々はMAX1000だとかCYC1000だとか、DE0-CVだとかの低価格帯ボードで出来るだけ高速に外部のCPUと通信させる必要があるわけですね。
2. CPUの強さ
アクセラレータを作るからにはCPUより高速に演算が出来なければアクセラレータとは呼べません。一般的なデスクトップやノートのCPUに対してのアクセラレータを作るのは上記の成約から明らかに無謀です。上記の低価格帯ボードでも計算をアクセラレート出来る程度に弱いマイコンに対してのアクセラレータにするべきです。ちなみにラズパイzeroには勝てません、あれ1000円の癖に1GHzで動いてます、こちらのFPGAは早くて100MHz、無謀ですね。
方針
何に対してのアクセラレータにするか、今回は上記の障害よりNucleo-f303k8に接続することを前提にします。
Nucleo-f303k8のCortex-M4Fは動作周波数が72MHz!手元のFPGAは早くて50MHz!ギリギリ希望が見えますね(みえない)。また通信方式はSPI(Serial Peripheral Interface)を採用します(50MHzで通信出来るらしい)。
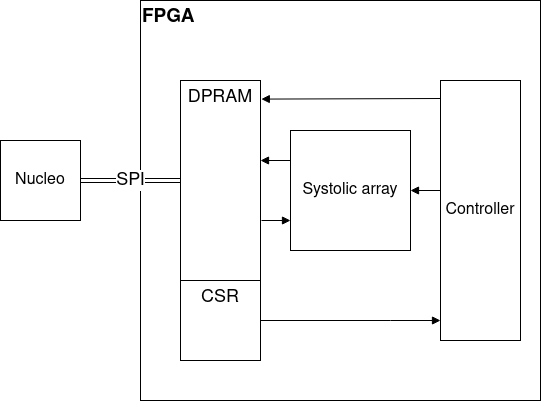
つまり最終的な外観は以下になります。

では次にアクセラレータの構成を決定しましょう。シストリックアレイをコアに、周囲には行列データ格納用のRAM、行列サイズ格納用のCSR、それら全てを制御するコントローラとするのが妥当な構成ですね。
実装
SystemVerilogで殴って!終わり!
で終わらせるのは流石に手抜きなのでPEのRTLだけ解説します。
module PE #( parameter WORD_SIZE = 16 )( input logic clk, input logic read, input logic reset, input logic [WORD_SIZE-1:0] l_d_i, input logic [WORD_SIZE-1:0] r_d_i, input logic [WORD_SIZE-1:0] t_d_i, output logic [WORD_SIZE-1:0] l_d_o, output logic [WORD_SIZE-1:0] r_d_o ); logic [WORD_SIZE-1:0] buffer_w; logic [WORD_SIZE-1:0] buffer; logic [WORD_SIZE-1:0] r_d_o_r; always_comb begin if(reset) begin buffer_w = '0; end else if(read) begin buffer_w = r_d_i; end else begin buffer_w = buffer + l_d_i * t_d_i; end r_d_o = r_d_o_r; if(read) begin l_d_o = buffer; end else begin l_d_o = '0; end end always_ff @(posedge clk) begin buffer <= buffer_w; r_d_o_r <= l_d_i; end endmodule
入出力のl_d_iは左からのデータ入力、t_d_iは上からのデータ入力、r_d_oは右へのデータ出力で、これらは前掲したPEの図に載っています。l_d_o、r_d_iは行列-ベクトル積を計算した結果を左側から出力するための線であり、入力のreadがHighになるとこれらの線は使われます。read、resetが0の場合、左と上から入力を掛け算し内部バッファの値と加算した値をbuffer_wに入力し、クロックの立ち上がりでbufferの値が更新されます。また同時に右へ入力する値を格納するバッファr_d_o_rの値も更新されます。
性能
SPIの通信速度は10MHzまでは安定に動作します。明らかにアクセラレータとしての性能を満たせませんね。かなしいね、知ってた。
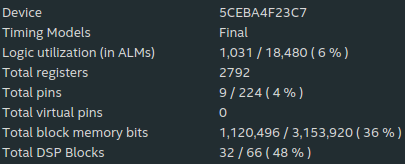
合成結果は以下の画像の通りです。
というか32x32以上のサイズで計算させるとバグるので世界終わってほしい。
テストベンチはこちら、mbed便利ですね
#include "mbed.h" SPI spi(A6, A5, A4); DigitalOut cs(A3); Serial pc(USBTX, USBRX); Timer tm; int main(){ cs = 1; spi.format(16, 0); spi.frequency(1000000); unsigned int A[31][31], B[31], C_1[31], C_2[31]; for(int i = 0; i < t; i++){ for(int j = 0; j < t; j++){ A[i][j] = j; } B[i] = i; } // ---- run on accelerator ---- cs = 0; tm.start(); spi.write(0x1001); // write vector size spi.write(0x001f); // size 31 spi.write(0x1002); // write matrix column size spi.write(0x001f); // size 31 spi.write(0x4000); // start input vector data for(int i = 0; i < 31; i++){ spi.write(B[i]); } spi.write(0x5000); // start input matrix data for(int i = 0; i < 31; i++){ for(int j = 0; j < 31; j++){ spi.write(A[j][i]); } } spi.write(0x3000); // start calculation spi.write(0x6000); // read result for(int i = 0; i < 31; i++){ C_1[i] = spi.write(0x0000); } tm.stop(); cs = 1; printf("The time taken was %d us\n\r", tm.read_us()); printf("The time taken was %d ms\n\r", tm.read_ms()); for(int i = 0; i < 31; i++){ printf("C_1[%d] = 0x%04x\n\r", i, C_1[i]); } tm.reset(); // ---- run on cpu ---- tm.start(); for(int i = 0; i < 31; i++){ C_2[i] = 0; } for(int i = 0; i < 31; i++){ for(int j = 0; j < 31; j++){ C_2[i] += A[i][j] * B[j]; } } tm.stop(); printf("The time taken was %d us\n\r", tm.read_us()); printf("The time taken was %d ms\n\r", tm.read_ms()); for(int i = 0; i < 31; i++){ printf("C_2[%d] = 0x%04x\n\r", i, C_2[i]); } }
適当に31x31行列の計算をさせた結果がこちら

マイコンのCPUで同じ計算をさせた結果がこちら
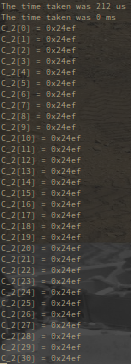
なんと0.01倍も高速化しました!おやすみなさい
参考文献

- 発売日: 2016/04/22
- メディア: 単行本(ソフトカバー)