Implementing Hardware Extensions for Multicore RISC-V GPUsを読む
RISC-V GPUへのハードウェア拡張の実装に関する論文の内容をサマライズしていく。
出典:https://carrv.github.io/2022/
経緯
ちょうど本日ISCAの併設CARRVでRISC-VのGPU拡張の論文が出ているので、サマライズして教えてください(笑)。https://t.co/C2T8McuydM
— Masayuki@FPGA開発日記 (@dev_msyksphinz) 2022年6月20日
Implementing Hardware Extensions for Multicore RISC-V GPUs https://t.co/PJa9LkvEzh
ベースとなってる Vortex: OpenCL Compatible RISC-V GPGPUの Micro 2021でのチュートリアルと MICRO 2021発表ペーパーです https://t.co/KnyNS7mMF6
— OGAWA, Tadashi (@ogawa_tter) 2022年6月20日
1stの博士課程の学生とラスト:Hyesoon Kim教授は一緒です、研究室 https://t.co/5el0C4MQGv
では、よろしくお願いします。
やるぞい
目次
- 経緯
- 要約
- 1. Introduction
- 2. BACKGROUND
- 3 A TOPOLOGY OF HARDWARE EXTENSIONS
- 4. RISC-V ISA EXTENSION
- 5. IMPLEMENTING EXTERNAL EXTENSIONS
- 6. HARDWARE PERFORMANCE COUNTERS
- 7. SAMPLE IMPLEMENTATION
- 8. RELATED WORK
- 9. CONCLUSION
要約
内容:RISC-VベースのGPUへのハードウェア拡張の効果的な実装方法の提案
マイクロアーキテクチャの方針
- アクセラレータは各コアの内側に実装するのが望ましい
- コア外部のアクセラレータにはキャッシュを付けると良い
- キャッシュを付けてレイテンシが改善されるならコア内部にアクセラレータを置いても良い場合がある
- アクセラレータのコンフィグにはCSRを使うと良い
- コアの外部にアクセラレータを置く場合、各コアにアクセラレータとの通信管理用のローカルエージェントを置く場合がある
- 同様のケースでアクセラレータがGPUのどのコアと通信するかを決めるマルチプレクサ/デマルチプレクサを使う場合がある
ISAの方針
- 自作の拡張命令で使えるオペコードは4つ
- 3つの引数が使えるR4フォーマットの利用を優先すべき
- 1命令が取る引数を増やしたい場合は隣接するビットフィールドをマージするのが最も望ましい
- 次点でファンクションビットを引数のフィールドとして扱う方法もある
- 命令の総数が減るのでオススメはしない
- CSRをアクセラレータの引数入れとして扱うのは推奨できない
- アクセラレータの利用に2命令必要になってIPCが下がる
- 追加した命令はコンパイラにも対応させた方が良い
- ハードウェアパフォーマンスカウンタ(そういうのがある)は枯渇しがちなのでクラス分けして使うと良い
感想:みんなもGPUを拡張する時は参考にしような!!
以下翻訳
1. Introduction
近年、RISC-V ISAをベースにしたGPUが発表され始めている。
https://ieeexplore.ieee.org/document/8918510
https://ieeexplore.ieee.org/document/6942056
https://carrv.github.io/2017/papers/collange-simty-carrv2017.pdf
これらのGPUはRISC-Vの整数乗除算や浮動小数点数演算などの標準拡張(MとかFとかDとか)を実装しているが、これに画像解析やグラフ解析、機械学習用の専用ハードウェアを追加するとなると標準拡張だけでは不十分であり、非標準の拡張を実装する必要がある。
しかし、専用ハード向けのISAとレジスタをRISC-Vと互換性を保ったまま実装したり、専用ハードをプロセッサに接続する手法は、未だに確立していない。
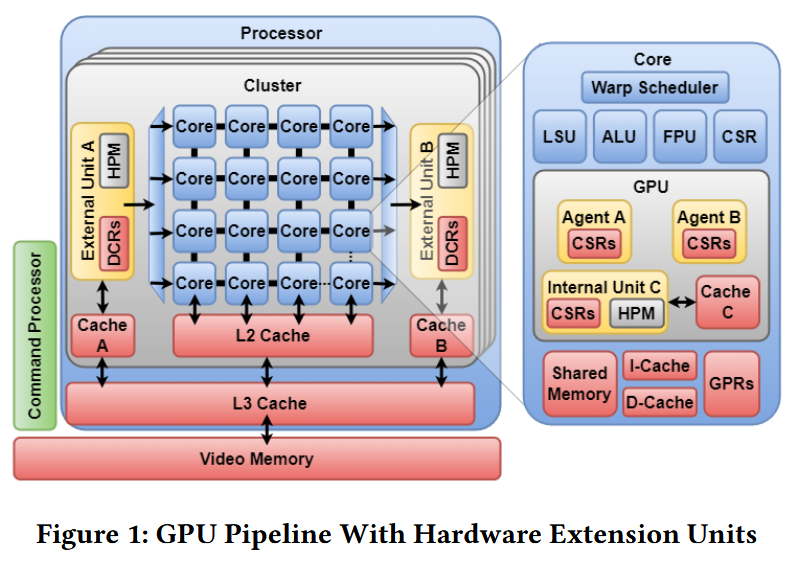
GPUと専用ハードA, B, Cの位置関係をFigure.1に示している。専用ハードの位置としてコアの上流にあるAや下流にあるB、Cのような他の標準拡張と似たように各コアの内側に存在している場合などが考えられる。
この論文ではRISC-VベースのGPUに対して、専用ハードウェア用の拡張を実装する一般化された手法を紹介している。この論文で紹介されている技術はなんとシングルコアまたはマルチコアのCPUにも適用することが可能とのこと。
提案手法はISAとマイクロアーキテクチャの両方を取り扱い、加えてオンボードで専用ハードを持つ計算機のためのハードウェアパフォーマンスカウンタ(そういうのがある)の一般的な手法の提供する。
この論文のkey contributionsは以下の通り
- デザインの設計要件とGPUとの相互作用の観点からのGPU拡張構成の提案
- RISC-VベースのGPUに対する一般的な拡張機能の実装手法の紹介
- オンボードで専用ハードを持つ計算機に対するハードウェアパフォーマンスカウンタの一般的な手法の提供
- RISC-VベースであるVortex GPUへの提案手法の適用
2. BACKGROUND
2.1 Processor Hardware Extensions
プロセッサは誕生したその頃から専用ハードが実装されてきており、その操作はISA拡張を介して行われてきた。GPUも計算を加速するために同様の手法を取ってきた。
2.1.1 CPU Hardware Extensions
CPUのハードウェア拡張は色々ある。FPUはもちろん暗号とか乱数生成とかNNとか。
2.1.2 GPU Hardware Extensions
GPUのハードウェア拡張は大部分をグラフィック用アクセラレータが占めており、ラスタライザとかテッセレーションとか色々ある。またFPUと共に機械学習用のハードウェアも実装されている。
2.2 RISC-V ISA Extension
2.2.2 User-Defined Extensions
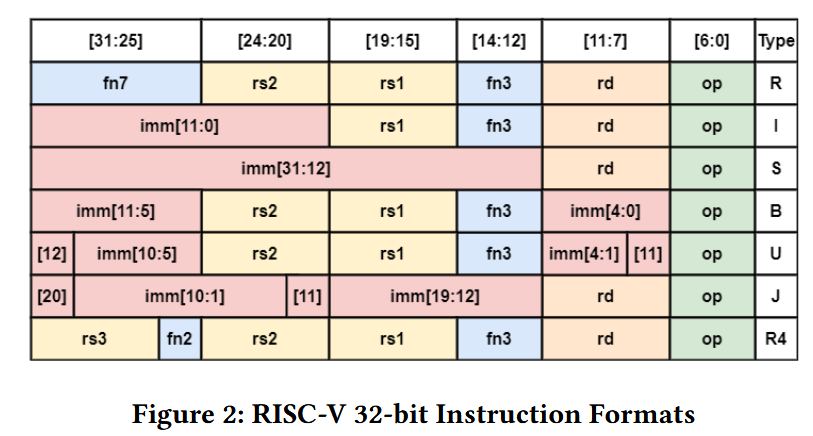
RISC-Vではユーザー定義用のオペコードに0x0B, 0x2B, 0x5B, 0x7Bが使える。命令フォーマットはFigure.2に沿うが、RISC-Vの整数命令のオペランドは最大2個、浮動小数点数命令だと最大3個であり、これだと十分でない場合がある。
2.2.3 Hardware Performance Monitoring Counters
性能の統計を評価するためにはハードウェアパフォーマンスカウンタ(そういうのがある)は必要不可欠であり、RISC-VではCSRのアドレス0xB00-0xB1F及び0xB80-0xB9FがHPM counter用に確保されている。
2.3 Vortex GPU Framework
VortexはRISC-VベースのSIMT GPUである。デザインはFPGAに最適化されており、最高250MHzで動作し、64コア1024スレッドとなっている。
2.3.1 Vortex ISA
Vortexには標準拡張に加え、wspawn, tmc, split, join, barの5つのSIMT実行モデル用とtexのテクスチャサンプリングの高速化用の命令が追加されている。
2.3.2 Software Stack
VortexはOpenCLをサポートしている。
2.3.3 Hardware Stack
Vortexのコアは5段パイプラインでFPUに加えてテクスチャ用アクセラレータを搭載している。
VortexはOpenCLコンパチらしいですね...おっとここに良質なOpenCL入門記事が。
3 A TOPOLOGY OF HARDWARE EXTENSIONS
普通のGPUにはハードウェア拡張として、浮動小数点数演算器(FPU)、固定小数点数積和演算器(IMADD)、SHA256変換器(sha256sum)、行列乗算器(MatMul)、ソフトウェアプリフェッチ(Prefetch)、頂点フェッチエンジン(VFetch)、ラスタライザ(Raster)、グラッフィクス属性補完(Interp)、テクスチャサンプリング(Tex)、アルファブレンド(Blend)がある。これらのプロセッサから見た分類をTable.1に示した。
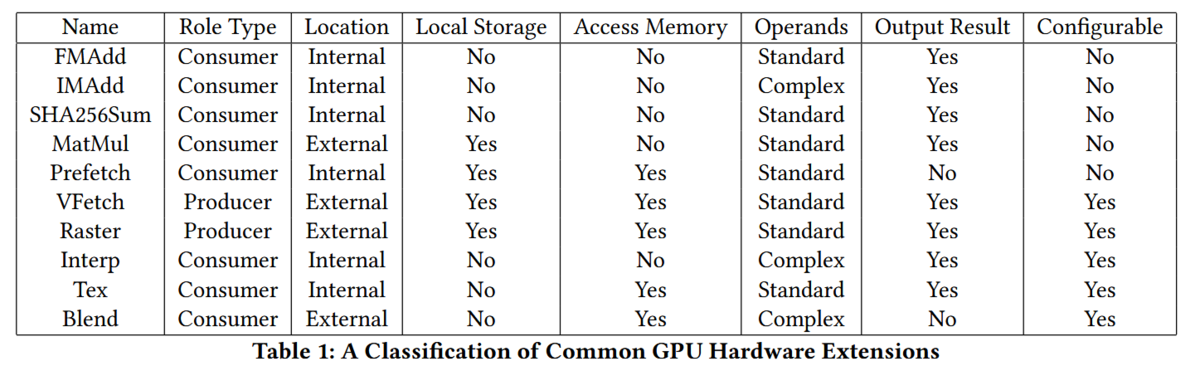
各ハードウェア拡張のオペランドをTable.2に示した。

3.1 Producer vs Consumer Extensions
ハードウェア拡張はプロセッサコアからデータを受け取るコンシューマと、プロセッサコアにデータを与えるプロデューサに分けられる。拡張の大多数はコンシューマであり、基本的にプロセッサコアにトリガされて動作する。また、プロデューサの拡張は常にコアにデータを提供し、処理すべきデータが無い場合はその旨をコアに伝える必要がある。
3.2 Internal vs External Extensions
ハードウェア拡張はその位置によっても分類される。ハードウェア拡張は回路面積や帯域の成約に応じて、コアの外側または内側に配置される。基本的に、ハードウェア拡張は内側に配置されるのが望ましい。これにはいくつかの利点が存在しており、1) ハードウェアをコア間で共有しないため、ハードウェア拡張-コア間の帯域幅を最大化出来る。これはハードウェア拡張がメモリアクセスを行わない場合に特に有効となる。 2) コア内の既存のインターフェースと統合出来るため、デザインの複雑性を低減出来る。内部への拡張の主な欠点は、各コアに新たな回路が追加されるため回路面積が増大する事が挙げられる。
ハードウェア拡張をどこに配置するかを決定する効果的な手法は、アプリケーションに必要な帯域幅を決める事である。
例えばアルファブレンド(Blend)は内側と外側どちらでも置くことは可能だが、ピクセルシェーダプログラムは繰り返される数百から数千の命令の最後の一回にしかこの命令を呼ばないため、アルファブレンド用のハードを内側に置いたところで無視できる程度の改善しか得られない。一方でテクスチャサンプリング(Tex)のハードウェアは内側に置くのが望ましい、これはこの命令がピクセルシェーダプログラムの各繰り返しで何度も呼ばれるためである。
3.3 Needing local storage
拡張にもよるが、行列乗算(MatMul)のように一時的にデータを保存するためのストレージが必要な場合がある。この実装は広いベクトルレジスタを持たないスカラプロセッサの場合によく合っている。(わからん)
3.4 Accessing Memory
メモリアクセスを必要とするハードウェア拡張は、コアの外側に位置する事が多い。これは主にメモリレイテンシが原因であり、コアからのアクセスを保留にする要求をキューに入れる必要があるからである。このようなハードウェア拡張は一般的にメモリ律速になり、これはハードウェアをコアの近くに置くことのメリットを低減させる。実際にはこの様なハードウェアはメモリレイテンシを減らす為にプライベートキャッシュと一体化される。テクスチャサンプラはメモリアクセスを行うにも関わらずコアの内側に存在している。これはリードオンリーのキャッシュメモリが付いており、メモリレイテンシが軽減されているためである。
3.5 Complex Operands
拡張命令を実装する上で重要な要素の一つが、入力をアクセラレータにどう与えるか、である。 拡張命令がソースオペランドをRISC-V ISAで定義されている以上に必要な場合(この場合3)、その命令は複雑なオペランド(Complex Operands)に分類される。複雑なオペランドをどう対処するかは性能へ影響を与える。この問題に対する戦略は後に説明する。
3.6 Configurable Extensions
ハードウェア拡張には使う前に動作や定数のコンフィグレーションを必要とするものが存在する。RISC-Vにおいてハードウェアをコンフィグレーションを際に最も推奨される方法が、Control status register(CSR)を使うことである。RISC-Vでは読み書き可能な512スロットのCSRと読み出し限定の192個のCSRが拡張の為に確保されている。
4. RISC-V ISA EXTENSION
ここではRISC-Vのための命令エンコーディングの拡張方法を解説する。
4.1 Instruction Encoding
新たな命令のために、RISC-Vでは0x0B, 0x2B, 0x5B, 0x7Bの4つのオペコードが用意されている。利用可能なオペコードは4つであり、将来の拡張のために可能な限り再利用することを考えると、主な難題は命令フォーマットを決める事となる。主に使われるのはfigure 3におけるRとR4の命令フォーマットである。
4.1.1 R format
Rフォーマットは最も柔軟なフォーマットであり、C=f(A, B) の形式の命令なら全てこれでよく、またfunc3とfunc7のフィールドによって1024通りの命令が定義可能だからである。
4.1.2 R4 format
R4フォーマットはオペランドの数が多い場合に最も良いフォーマットであり、3つのオペランドを持つことが可能である。ただその欠点として、func3とfunc2の32通りの命令しか定義出来ない。
実際には命令フォーマットはR4の実装が優先され、最低でも2つのオペコードで使われる。これはGPUのハードウェア拡張では2つ以上のオペランドが要求される事が多いからである。
4.2 Operands Extension
オペランドを3つ以上要求するハードウェア拡張において、パラメータをどのように渡すかはその性能に大きな影響を与える。本論文では3つ以上のオペランドの扱い方を3種類に分けて検証した。
4.2.1 Inputs Merging
最も効果的な方法は、Figure 5のように単純に複数のビットフィールドをマージする方法である。これはBlendのように引数の数が固定されず、複数のオペランドとなる場合と、複数のオペランドが連結して一つのオペランドになる場合に非常に効果的となる。(なぜ?)
4.2.2 Functions Merging
引数をマージ出来ない場合、次に取れる選択はFigure 6のようにファンクションビットをまとめて追加のレジスタとする方法である。これはR3フォーマット(謎)では2つのオペランドを追加でき、R4フォーマットでは1つのオペランドを追加することが可能である。これには2の欠点があり、1) これはファンクションビットをオペランドに使うため、トータルの命令数を減らしてしまう。2) ソースオペランドの数を増やすと、追加のレジスタを読み込むことでバックエンドが複雑になるため、既存のパイプラインでサポートされているレジスタファイルへの依存性が生まれる。
4.2.3 Control Status Registers
最後の手段としてCSRを経由してオペランドを与える方法があるが、この方法は実行をCSR操作命令と普通の命令の2つに分ける事になるため全く効率的ではない。まずCSR命令はパイプラインをストールさせ、拡張命令の呼び出しの度にCSR操作命令も必要になるためIPCに影響を与える。
4.3 Software Support
ソフトウェアレイヤにおいて、アプリケーションは新たに追加された命令を実行する必要がある。最も優先される方法はコンパイラへの新たな命令の実装である。この方法の主な利点が高レベルのコード変換が可能となることである(謎)。その他の利点としてアセンブラと逆アセンブラによるデバッグへの恩恵が挙げられる。 コンパイラへの追加の代替案としてはListing 1のようなバイトコードをラップした組み込み関数がある。

5. IMPLEMENTING EXTERNAL EXTENSIONS
外部にハードウェア拡張を実装することは、複数のプロセッサによってそのハードウェアが共有される点において熟考に値する。
5.1 Local Agents
ローカルエージェントはコア内にある軽量のモジュールであり、外部のハードウェアとの通信を管理する。ローカルエージェントは発行された命令を外部のハードウェアで実行できるようにスケジューリングし、必要であればコア毎のローカルストレージの管理も行う。
Figure 1で外部のハードウェアA, BのためのローカルエージェントA, Bが示されている。
5.2 Arbitration
外部のハードウェアに対するアクセスの調停は柔軟なマルチプレクサ/デマルチプレクサによって行われる。どちらを用いるかはハードウェア拡張がコンシューマかプロデューサかによるが、その柔軟性はデータの適切なハンドシェイクの役に立つ。Figure 1ではAでデマルチプレクサが使われ、Bでマルチプレクサが使われているのが示されている。
6. HARDWARE PERFORMANCE COUNTERS
ハードウェアパフォーマンスカウンタ(そういうのがある)はハードウェアの性能の測定とデバッグに必要不可欠である。RISC-V ISAでは32個のカウンタしか定義されておらず、またそのうち3つは予約されている。 ハードウェア拡張を計測するためのハードウェアパフォーマンスカウンタを実装する際、これは非常に枯渇しやすい。ハードウェア拡張が無い場合でさえも、通常のパイプラインを構築するだけでかなりのハードウェアパフォーマンスカウンタを消費する。我々は単純なデータキャッシュの計測でさえ、最低でも半分のカウンタを消費する事に気づいた。
6.1 Hardware Implementation
カウンタの上限の回避策として、カウンタをカテゴリ分けする方法が挙げられる。コンポーネントに基づくカテゴリ分けがオススメである。具体的にはプロセッサパイプラインをクラス0、命令キャッシュをクラス1、データキャッシュをクラス2とする。この実装ではクラスの選択に非標準のCSRを用いることが出来る。Figure 8にマルチプレクサを用いた単純な実装を示した。なお、HPMのスロット0, 1, 2は予約されているためマルチプレクサからは除外している。

6.2 Software Support
ハードウェアパフォーマンスカウンタからのデータを得る最も自然な方法は、カウンタの内容をメモリにダンプする方法である。ホストCPUが読むためのメモリ空間を予約して実装する。最長のキャプチャを得るために、プログラム終了時にカウンタをフラッシュするのが好ましい。これはmain関数からリターンした後の_exit()関数内でダンプを実行する形で実装する。
7. SAMPLE IMPLEMENTATION
この項では我々がVortex GPUに対して行った固定小数点数積和演算について解説する。固定小数点演算はグラフィックスにおいて浮動小数点数演算の近似によく用いられる。
7.1 ISA Encoding
固定小数点数積和演算は、以下のように定義される。
この命令のフォーマットは3オペランドのR4フォーマットを用いている。また、この演算における定数Fは多くの場合8, 16, 24を取るため、R4フォーマットのfunc2のフィールドが0->0, 1->8, 2->16, 3->24としている。 これはfunc2を3ビットシフトで得られる。 このエンコーディングによって、同じハードウェアで整数の積和演算を行うことが可能になり、拡張の価値を高めることが出来る。
7.2 Microarchitecture
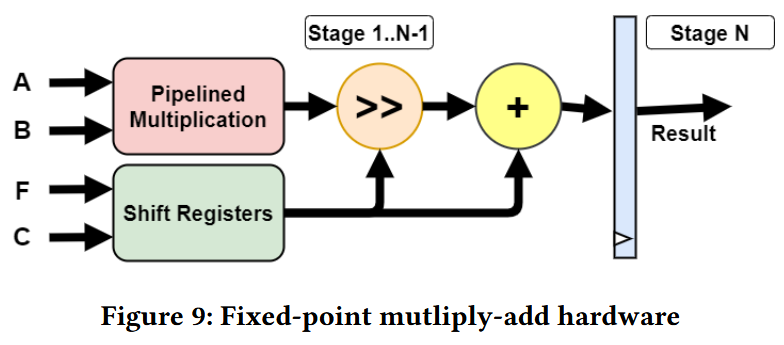
Figure 9はハードウェア拡張のマイクロアーキテクチャであり、これはAとBの乗算を複数サイクルに渡って行うパイプライン化された乗算器と、FとCを同期しながら加算器とシフタに渡すシフトレジスタから構成される。
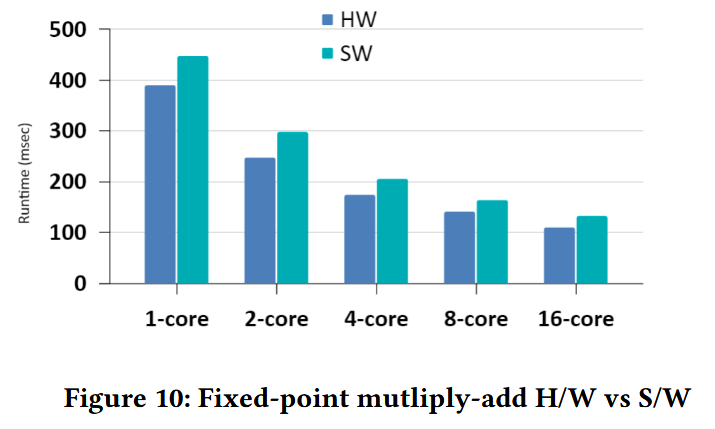
7.3 Evaluation
Figure 10は固定小数点数演算命令を複数回呼び出すプログラムの、ハードウェア拡張とソフトウェア実装の比較である。なと200MHzのArria 10 FPGAで動作している。 結果を見ると、ソフトウェアとハードウェア両方でコアの数に対してよくスケールしている。我々のハードウェア拡張はソフトウェア実装に対して17-20%程優れているが、これは大きな改善という程でもない。これはソースオペランドがメモリから値を読んでいるため、プログラム内でオーバヘッドが生じているのが原因である。
8. RELATED WORK
Austinの論文ではVortex GPUにRISC-Vの暗号拡張を追加しており、筆者は公式のRISC-Vの暗号拡張を実装に用いた。彼らはハードウェアを各コアの内部に実装し、AES256とSHA256に対してそれぞれ6.6倍と1.6倍の高速化が得られた。
Kuoの論文では暗号におけるガロア体演算の拡張を提案し、4つの非標準拡張命令を実装した。ハードウェアは各コアの実行ユニットの内部に追加され、ソフトウェア実装に比べ77%のクロックサイクルの削減が達成された。
9. CONCLUSION
本論文ではRISC-Vプロセッサに対してハードウェア拡張を行う上での様々な難題に対して議論した。我々は性能とコストに基づいて様々な選択肢を提案し、比較した。 またRISC-V ISAは、拡張命令のサポート、非標準のCSR、ハードウェアパフォーマンスカウンタ等のハードウェア拡張を行うための豊富な機能が用意されている。 デザインのコストと利益を理解した上で、それらの機能を有効に活用することはアーキテクトの腕に掛かっている。
軽率にGPUを使っていこう、OpenCL入門
はい、Cra2yPierr0tです。GPUを作る前に市販のGPUを触ってみるか、どうやらOpenCLってやつが標準化されてて良さそうだぞ。という動機でOpenCLを書き始めたら思いのほか辛かったし納得のいく入門記事が無かったので備忘録がてらOpenCL入門をここに置いときます。
目次
- OpenCLとは
- OpenCLの思想
- OpenCLの計算機システム
- ホストとカーネル
- OpenCLの次元
- OpenCLホストプログラミング入門
- OpenCLカーネルプログラミング入門
- カーネルの最適化
- おわりに
OpenCLとは
並列プログラミング用のAPI、厳密な定義はwiki読んでね。
あとインストールとかは各自で頑張ってください。
OpenCLの思想
OpenCLの思想としてループの関数(カーネル)への展開が挙げられる。例として以下のように1024x1024の画像処理を1個のカーネルで行うのではなく、1024x1024=1,048,576個のカーネルで行うことで処理を高速にする。
古典的な実装
void mul(const int n, const float *a, const float *b, float *c) { for(int i = 0; i < n; i++){ c[i] = a[i] + b[i]; } }
OpenCLでデータ並列性を活用する
// これが同時に大量に実行される __keren void add(__global const float *a, __global const float *b, __global float *c){ int id = get_global_id(0); c[id] = a[id] + b[id]; }
OpenCLの計算機システム
OpenCLにとって計算機システムは、単一の制御用のホストと一つ以上のデバイスによって構成されている。そしてデバイスは一つ以上のCompute Unit(CU) からなる。またCUも一つ以上のProcessing Element(PE) から構成される。
メモリシステムもホストメモリとデバイスメモリに大別される。ホストとデバイスを合わせてプラットフォームとも呼ぶ。

ホストとデバイスが何を指すかは覚えておいた方が良い。
ホストとカーネル
OpenCLのプログラムは、GPU上で動くカーネルプログラムとCPU上で動くホストプログラムに分かれている。
カーネルプログラムはGPUで動くプログラムであり、カーネルプログラムが大量に並列実行されることで高速な計算が可能となる。またホストプログラムはCPU上で動くプログラムであり、その主な役割はカーネルプログラムをGPUへ展開する事と、データを転送する事である。
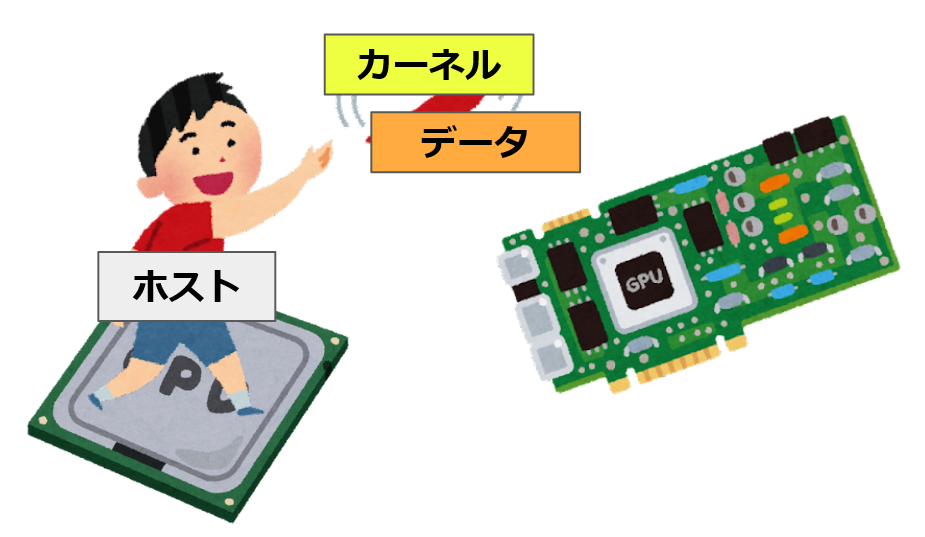
以上の通りOpenCLではホストとカーネルの二種類のプログラムを書く必要があり、特にホストプログラムはやることも多く複雑になりやすい。ホストとカーネルとは何かをきちんと覚えた上で読み進めてほしい。
OpenCLの次元
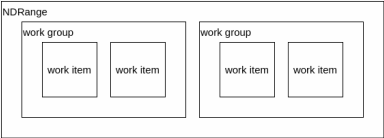
解きたい問題には全て、直線状やキューブ状や平面状のようにある程度の次元性が存在している。 OpenCLでは最大3次元までを指定してカーネルを展開する。また各次元方向のサイズも指定する必要がある。この各次元のサイズをグローバルサイズと呼ぶ。そして各点はワークアイテムによって処理される。
このワークアイテムを纏めたものをワークグループと呼ぶ。1つのワークグループに1つのCUが割り当てられ、ワークグループ内ではローカルメモリの共有と同期が可能である。
ワークグループ内にあるワークアイテムの数を指定することが可能であり、これをローカル(ワークグループ)サイズと呼ぶ。OpenCLランタイムにこのローカルサイズを自動に決定させることも可能だが、大抵の場合最適ではない。
アルゴリズムに最も適した次元を選ぶことが非常に重要である。

OpenCLの基礎知識は以上にとどめ、次は具体例を出しながらホストプログラムの書き方を解説する。
OpenCLホストプログラミング入門
概要
ホストプログラムは基本的に5つのステップに分けられる。
1. デバイス, コンテキスト, コマンドキューを定義する
コンテキスト、キューという概念が出てきた、コンテキストは利用するデバイスをまとめた実況環境(らしい)であるが、OpenCLを使うために必要なオブジェクトというフワッとした解釈で全然問題ない。
コマンドキューに関しては割と重要な概念である。これはコマンド(カーネル及びメモリ等の転送命令)が入るキューであり、デバイスでプログラムを実行するにはこのキューを必ず経由する必要がある。 一つのコマンドキューは一つのデバイスに向かっており、複数のコマンドキューが同じデバイスに向かう事も可能である。この場合、コマンドキュー同士で同期を取る必要は無い。
よってより正確なイメージは以下のようになる。
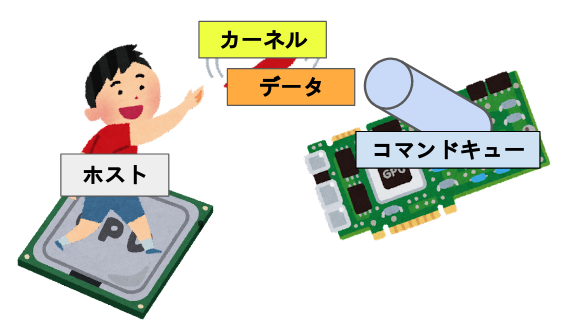
コマンドキューだが、キューに入れた順にデバイスに送るインオーダキューと、入れた順にならないアウト・オブ・オーダーキューが存在する。
主に使う関数はこちら
- 利用可能なプラットフォームを確保:
clGetPlatformIDs()
- デバイスを確保
clGetDeviceIDs()
- コンテキストを作成
clCreateContext()
- コマンドキューを作成
clCreateCommandQueue()
これらの関数を使って必要なものを定義するコードが以下になる。また先頭にclが付いている型や関数はOpenCL APIで定義されているものである。
// 環境構築関係 // プラットフォームIDを確保 cl_platform_id platform_id; cl_uint platform_num; clGetPlatformIDs(1, &platform_id, &platform_num); // デバイスIDを確保 cl_device_id device_id; clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_DEFAULT, 1, &device_id, NULL); // コンテキストを作成 cl_context context; context = clCreateContext(0, 1, &device_id, NULL, NULL, NULL); // コマンドキューを作成 cl_command_queue commands; commands = clCreateCommandQueue(context, device_id, 0, NULL);
2. カーネルをビルドする
カーネルプログラムもプログラムであるので、コンパイルして実行形式にしてやる必要がある。OpenCLではカーネルプログラムからプログラムオブジェクトを作成し、そのプログラムオブジェクトをビルドした後カーネルオブジェクトを作成する。
コンパイル方式には、事前にカーネルプログラムをコンパイルするオフラインコンパイルと、ホストプログラムの実行時にコンパイルするオンラインコンパイルの二種類の方式がある。
主に使う関数がこちら
- プログラムオブジェクトを作成
clCreateProgramWithSource()
- プログラムオブジェクトをビルド
clBuildProgram()
- カーネルオブジェクトを作成
clCreateKernel()
これらの関数を使ってカーネルオブジェクトを作成するコードが以下になる。clCreateProgramWithSource()の引数であるkernelsourceはカーネルプログラムを保持している文字列である。
// プログラムオブジェクトを作成 cl_program program; program = clCreateProgramWithSource(context, 1, (const char **)&kernelsource, NULL, NULL); // プログラムオブジェクトをビルド clBuildProgram(program, 0, NULL, NULL, NULL, NULL); // カーネルオブジェクトを作成 cl_kernel ko_vadd; ko_vadd = clCreateKernel(program, "vadd", NULL);
3. デバイスメモリを確保する
データを格納するためにCPUでメモリを確保するのと同様に、GPUのメモリを確保してやる必要がある。
例として、ベクトル加算を行う場合、3つのメモリオブジェクトが必要になる。a, bを入力ベクタとして、cを出力ベクタとする。 先にホスト側でメモリを確保し、適当に初期化する。
// ホストメモリを確保 float h_a[1024], h_b[1024], h_c[1024]; for(int i = 0; i < 1024; i++) { h_a[i] = rand() / (float)RAND_MAX; h_b[i] = rand() / (float)RAND_MAX; }
次にデバイスメモリを確保し、メモリオブジェクトを得る。関数はclCreateBuffer()を使う。この関数を使ってメモリを確保するコードが以下になる。
// デバイスメモリを確保 cl_mem d_a; cl_mem d_b; cl_mem d_c; d_a = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_a, NULL); d_b = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_b, NULL); d_c = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * 1024, NULL, NULL);
clCreateBuffer()の引数を見てみると、入力ベクタにはCL_MEM_READ_ONLYやCL_MEM_COPY_HOST_PTR、ホストメモリへのポインタが指定されていたり、出力ベクタにはCL_MEM_WRITE_ONLYが指定されていたりと、なんとなく何を意図して引数を設定しているか分かるかもしれない。分からなければ後でリファレンスを読めばよい。
4. カーネルの引数を設定する
カーネルには関数のように引数を設定する事が可能である。引数を設定するにはclSetKernelArg()を用いる。
例としてベクトル加算を行う場合、カーネルに渡す必要がある引数は配列a, b, cのアドレスである。第一引数をfloat *a、第二引数をfloat *b、第三引数をfloat *cとして、カーネルに引数を設定するコードが以下になる。
// 引数を設定 clSetKernelArg(ko_vadd, 0, sizeof(cl_mem), &d_a); clSetKernelArg(ko_vadd, 1, sizeof(cl_mem), &d_b); clSetKernelArg(ko_vadd, 2, sizeof(cl_mem), &d_c);
5. キューにメモリとカーネルを転送する
コマンドキューにメモリの書き込み指示、カーネルの展開・実行の指示、メモリの読み出し指示を行う。
主に使う関数がこちら
- デバイスメモリにデータを書き込む、今回はデバイスメモリ確保時に行っているので使わない(疑問点あり)
clEnqueueWriteBuffer()
- カーネルをデバイスに展開し、実行する。後で詳しく扱う
clEnqueueNDRangeKernel()
- カーネルが完了まで待機する
clFinish()
- デバイスメモリからデータを読み出し
clEnqueueReadBuffer()
これらの関数を用いたコードが以下になる。
// カーネルをエンキュー size_t N = 1024; clEnqueueNDRangeKernel(commands, ko_vadd, 1, NULL, &N, NULL, 0, NULL, NULL); // 完了まで待つ clFinish(commands); // 結果を読み出し clEnqueueReadBuffer(commands, d_c, CL_TRUE, sizeof(float) * 1024, h_c, 0, NULL, NULL);
このcnEnqueueNDRangeKernel()がカーネルをどんな形で展開するかを決める非常に重要な関数である。これに関してはカーネルプログラムの書き方を解説する際に詳しく扱う。
ベクトル加算のホストプログラム
以上の1~5を組み合わせて完成させたホストプログラムが以下になる。一番下に計算結果の出力とクリーンアップを追加している。ライブラリとkernelsource、一番下以外は全て前述したコードと同じである。
OpenCLがインストールされている環境下で$ gcc -lOpenCL vadd.cでコンパイルが出来る。
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <time.h> #ifdef __APPLE__ #include <OpenCL/opencl.h> #include <unistd.h> #else #include <CL/cl.h> #endif char *kernelsource = "__kernel void vadd ( \n" \ " __global float *a, \n" \ " __global float *b, \n" \ " __global float *c) { \n" \ " int i = get_global_id(0); \n" \ " c[i] = a[i] + b[i]; \n" \ "} \n" \ "\n"; int main(int argc, char** argv) { // 環境構築関係 // プラットフォームIDを確保 cl_platform_id platform_id; cl_uint platform_num; clGetPlatformIDs(1, &platform_id, &platform_num); // デバイスIDを確保 cl_device_id device_id; clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_DEFAULT, 1, &device_id, NULL); // コンテキストを作成 cl_context context; context = clCreateContext(0, 1, &device_id, NULL, NULL, NULL); // コマンドキューを作成 cl_command_queue commands; commands = clCreateCommandQueue(context, device_id, 0, NULL); // プログラム関係 // プログラムオブジェクトを作成 cl_program program; program = clCreateProgramWithSource(context, 1, (const char **)&kernelsource, NULL, NULL); // プログラムオブジェクトをビルド clBuildProgram(program, 0, NULL, NULL, NULL, NULL); // カーネルオブジェクトを作成 cl_kernel ko_vadd; ko_vadd = clCreateKernel(program, "vadd", NULL); // メモリ関係 // ホストメモリを確保、適当に初期化 float h_a[1024], h_b[1024], h_c[1024]; for(int i = 0; i < 1024; i++) { h_a[i] = (float)(rand() % 10); h_b[i] = (float)(rand() % 10); } // デバイスメモリを確保 cl_mem d_a; cl_mem d_b; cl_mem d_c; d_a = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_a, NULL); d_b = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_b, NULL); d_c = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * 1024, NULL, NULL); // 引数とか // 引数を設定 clSetKernelArg(ko_vadd, 0, sizeof(cl_mem), &d_a); clSetKernelArg(ko_vadd, 1, sizeof(cl_mem), &d_b); clSetKernelArg(ko_vadd, 2, sizeof(cl_mem), &d_c); // 実行関係 // カーネルをエンキュー size_t N = 1024; clEnqueueNDRangeKernel(commands, ko_vadd, 1, NULL, &N, NULL, 0, NULL, NULL); // 完了まで待つ clFinish(commands); // 結果を読み出し clEnqueueReadBuffer(commands, d_c, CL_TRUE, 0, sizeof(float) * 1024, h_c, 0, NULL, NULL); for(int i = 0; i < 1024; i++) { printf("h_c[%d] = %f\n", i, h_c[i]); } // クリーンアップ clReleaseMemObject(d_a); clReleaseMemObject(d_b); clReleaseMemObject(d_c); clReleaseProgram(program); clReleaseKernel(ko_vadd); clReleaseCommandQueue(commands); clReleaseContext(context); return 0; }
なお、このプログラムはエラー処理を一切行っていないため、テンプレートとして使うことは全く推奨しない。
OpenCLカーネルプログラミング入門
前章のホストプログラムにおけるカーネルプログラムは次のようなものだった。
__kernel void vadd ( __global float *a, __global float *b, __global float *c) { int i = get_global_id(0); c[i] = a[i] + b[i]; }
get_global_id(0)だとか__globalだとか、いくつか見慣れない修飾子や関数があるだろう。これはOpenCLのカーネルプログラミングで用いる独自に拡張されたC言語の追加要素である。なお、この拡張されたC言語は文献によってはOpenCL Languageと呼ばれている。
ちなみに、配列のインデックスを取得しているget_global_id()関数だが、これは直線に並んでいるワークアイテムの位置を取得する関数である。前項のホストプログラムは、ワークアイテムという仮想的なプロセッサを直線状に1024個生成し、それら全てにこのカーネルプログラムを実行させている。実行されているカーネルは同一だが、get_global_id()が返す値がワークアイテムの位置によって異なるため、1024要素のベクトル加算を実現することが出来る。This is SIMD.
以降では、OpenCLによるCの拡張要素とカーネルプログラムの書き方について解説する。
OpenCLカーネルにおけるC言語
拡張されたC言語の概要は以下の通り。
- ISO C99からの派生である
- 組み込みデータ型
- スカラ型, ベクタ型, ポインタ
- 型変換関数
- 画像用データ型
- 組み込み関数 - 必須
- work-item用関数(そういうのがある) ,math.h, 画像の読み書き
- Relational関数(そういうのがある), Geometric関数, 同期関数
- 組み込み関数 - Optional
- 倍精度, アトミック命令
- 丸めモードの選択, image3d_t surfaceへの書き込み
- 関数修飾子
- アドレス空間修飾子
- ワークアイテム関数
get_work_dim(),get_global_id(),get_local_id(),get_group_id()等が存在する
- 同期関数
- Barriers : ワークグループ内の全てのワークアイテムは続行する前にバリア関数を実行しなければならない
- Memory fences : メモリ操作の順序を提供する
OpenCLカーネルのC言語における制約
拡張されたC言語において、いくつか機能が制約されている。
- 関数ポインタは使用できない
- ポインタのポインタはカーネル内では利用できるが、カーネルの引数としては利用できない
- ビットフィールドは利用できない
- 動的配列及び構造体は利用できない
- 再帰は利用できない(まだ)
- double型は予約語だがOpenCL v1.1においてはOptional
OpenCLのメモリモデル
OpenCLのメモリにはいくつか種類が存在する。カーネルプログラミングとは少し離れるが、__globalや__privateの意味を理解するには必須の要素であり、また良い性能を発揮するには理解が必要不可欠の要素であるので、ここで解説する。
- プライベートメモリ
- ワークアイテム毎に持ってるメモリ
- 最も高速で最も小さい: O(10) words/WI(Work-Item)
- ローカルメモリ
- ワークグループ内で共有されるメモリ
- ワークグループ間では共有されない
- O(1~10) Kbytes/Work-Group
- ローバル/定数メモリ
- 全てのワークグループから見えるメモリ
- グローバルメモリ:O(1~10) Gbytes
- 定数メモリ:O(10~100) Kbytes
- ホストメモリ
- CPU側のメモリ
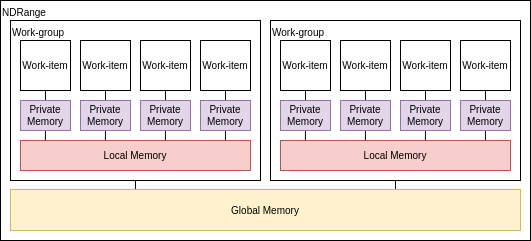
メモリ管理は明示的であり、プログラマはホストメモリ->グローバルメモリ->ローカルメモリの順にデータが移動される事に責任を持つ(逆方向も然り)。 ホストメモリ-グローバルメモリ間はO(1~10) Gbytes/s程度の帯域がある。
例:直列から並列へ
この項では行列乗算を例に、逐次実行のプログラムを並列実行のカーネルに書き換える流れを見せる。
行列乗算:愚直な実装
以下はサイズNの行列A, Bの行列積を計算し、Cに格納するプログラムである。
void mat_mul(int N, float *A, float *B, float *C) { int i, j, k; for(int i = 0; i < N; i++) { for(int j = 0; j < N; j++) { for(int k = 0; k < N; k++) { C[i*N + j] += A[i*N + k] * B[k*N + j]; } } } }
行列乗算:OpenCLカーネル(1/2)
まずは関数修飾子とアドレス空間修飾子を付ける
__kernel void mat_mul ( const int N, __global float *A, __global float *B, __global float *C ) { int i, j, k; for(int i = 0; i < N; i++) { for(int j = 0; j < N; j++) { for(int k = 0; k < N; k++) { C[i*N + j] += A[i*N + k] * B[k*N + j]; } } } }
行列乗算:OpenCLカーネル(2/2)
そして外側のループを取り除いてワークアイテムの座標をセットする
__kernel void mat_mul ( const int N, __global float *A, __global float *B, __global float *C ) { int i, j, k; i = get_global_id(0); j = get_global_id(1); for(int k = 0; k < N; k++) { C[i*N + j] += A[i*N + k] + B[k*N + j]; } }
行列乗算:改善されたOpenCLカーネル
Cの中間変数を置くとパフォーマンスが上がる
__kernel void mat_mul ( const int N, __global float *A, __global float *B, __global float *C ) { int i, j, k; i = get_global_id(0); j = get_global_id(1); float tmp = 0.0f; for(int k = 0; k < N; k++) { tmp += A[i*N + k] + B[k*N + j]; } C[i*N + j] += tmp; }
次はget_global_id()の正確な使い方や、ワークアイテムを思い通りの形に展開する方法を説明する。
ワークアイテム組み込み関数
上記のOpenCLカーネルでは、get_global_id()といった関数を使用してインデックスを取得していた。この関数はOpenCLにおいてワークアイテム組み込み関数に分類され、カーネルが実行されているCUの位置や、全体のサイズ等を取得するための関数である。OpenCLではこれらの関数から得られた値を元にメモリへアクセスを行う。
OpenCL 1.0におけるワークアイテム組み込み関数は以下の通り
| 関数名 | 説明 |
|---|---|
| get_work_dim | 次元の数を返す |
| get_global_size | 全体のワークアイテムの数を返す |
| get_global_id | グローバルワークアイテムIDを返す |
| get_local_size | ローカルのワークアイテムの数を返す |
| get_local_id | ローカルワークアイテムIDを返す |
| get_num_groups | ワークグループの数を返す |
| get_group_id | ワークグループIDを返す |
カーネルとインデックスの展開
GPUへのカーネルの展開はclEnqueueNDRangeKernelによって行われる。
cl_int clEnqueueNDRangeKernel ( cl_command_queue command_queue, cl_kernel kernel, cl_uint work_dim, const size_t *global_work_offset, const size_t *global_work_size, const size_t *local_work_size, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event)
work_dimでワークアイテムとワークグループの次元を設定し、global_work_sizeで全てのワークアイテムの数を設定する。これはsize_t型の配列を引数に取り、{8, 8}で64個、{8}で8個のワークアイテムが生成される。local_work_sizeではワークグループ内におけるワークアイテムの数を設定し、設定方法はglobal_work_sizeと同一である。
clEnqueuNDRangeKernelとワークアイテム組み込み関数の対応を図式すると以下の通りになる。
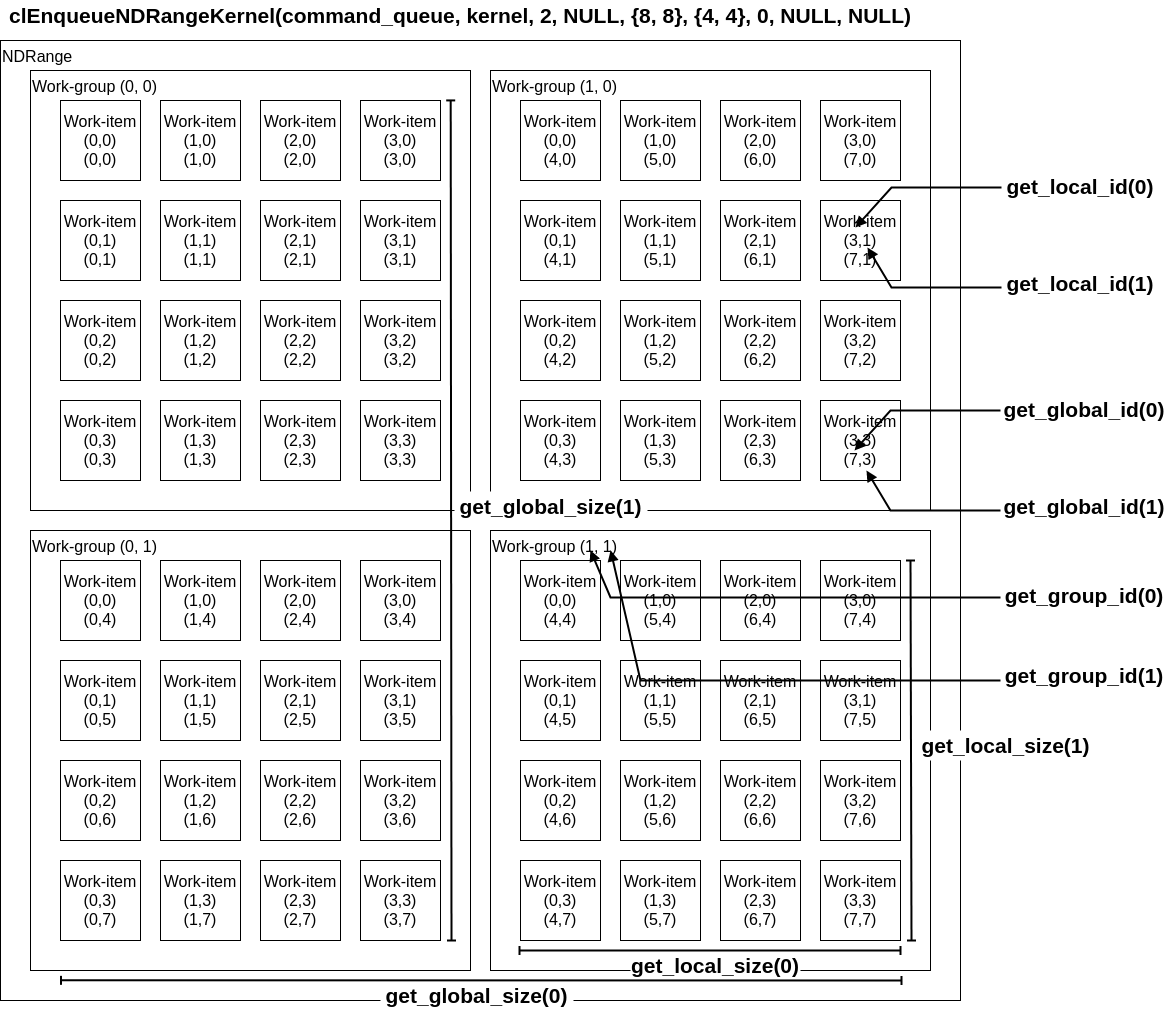

性能を出すためには問題に最も適したwork_dimとglobal_size、local_sizeを選ぶことが重要である。
OpenCLにおけるデータ型
ホストプログラムではcl_uintやcl_memのような独自の型が使われていた。カーネルでも同様に、OpenCLによっていくつか型が追加されている。
スカラーデータ型
| カーネルにおける型 | ホストにおける型 | 説明 |
|---|---|---|
| bool | n/a | true又はfalseが格納される。trueは1として解釈され、falseは0として解釈される。 |
| char | cl_char | 符号付き8bit整数 |
| unsigned char, uchar | cl_uchar | 符号なし8bit整数 |
| short | cl_short | 符号付き16bit整数 |
| unsigned short, ushort | cl_ushort | 符号なし16bit整数 |
| int | cl_int | 符号付き32bit整数 |
| unsigned int, uint | cl_uint | 符号なし32bit整数 |
| long | cl_long | 符号付き64bit整数 |
| unsigned long, ulong | cl_ulong | 符号なし64bit整数 |
| float | cl_float | 単精度浮動小数点数 |
| half | cl_half | 半精度浮動小数点数 |
| size_t | n/a | sizeof演算子が返す符号なし整数。clGetDeviceInfoにおけるCL_DEVICE_ADDRESS_BITSが32bitで定義されていれば32bitとなり、64bitで定義されていれば64bitとなる。 |
| ptrdiff_t | n/a | 2つのアドレスの減算結果が返す符号付き整数。clGetDeviceInfoにおけるCL_DEVICE_ADDRESS_BITSが32bitで定義されていれば32bitとなり、64bitで定義されていれば64bitとなる。 |
| intptr_t | n/a | 符号付き整数。voidへのポインタをこの型に変換とその逆が可能であり、またその結果は元のポインタと等しくなる。 |
| uintptr_t | n/a | 符号なし整数。voidへのポインタをこの型に変換とその逆が可能であり、またその結果は元のポインタと等しくなる |
| void | void |
ベクトルデータ型
ベクトルデータ型で値をまとめる事が出来る。に指定する値によってサイズが変わり、
には2, 4, 8, 16のいずれかを指定出来る。
| カーネルにおける型 | ホストにおける型 | 説明 |
|---|---|---|
| char |
cl_char |
符号付き8bit整数ベクトル |
| uchar |
cl_uchar |
符号なし8bit整数ベクトル |
| short |
cl_short |
符号付き16bit整数ベクトル |
| ushort |
cl_ushort |
符号なし16bit整数ベクトル |
| int |
cl_int |
符号付き32bit整数ベクトル |
| uint |
cl_uint |
符号なし32bit整数ベクトル |
| long |
cl_long |
符号付き64bit整数ベクトル |
| ulong |
cl_ulong |
符号なし64bit整数ベクトル |
| float |
cl_float |
単精度浮動小数点ベクトル |
一般行列ベクトル積を書いてみよう
習うより慣れろ、ということで線形代数演算APIであるBLAS(そういうのがある)のSGEMV、単精度行列-ベクトル積をOpenCLで実装してみよう。
SGEMV
単精度行列-ベクトル積SGEMVは以下の演算を行う。
| 変数名 | 説明 |
|---|---|
| |
スカラー |
| |
行列 |
| |
ベクトル |
| |
スカラー |
| |
ベクトル |
なお、ベクトルは全て列ベクトルとして扱われる。また行列の行サイズをN, 列サイズをMとする。
とりあえずカーネルプログラムを書く
このSGEMVをどうにか並列に実行したい。パッと思いつくのはワークアイテムを一次元に展開しての行毎に実行しやる方法だろう。
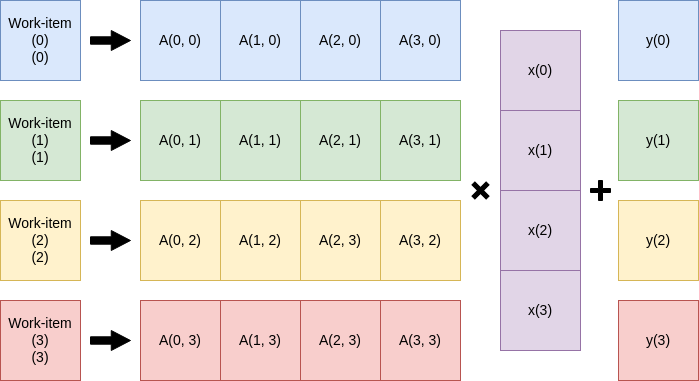
は省略)
性能が出るかは知らないがとりあえず実装してみる。
__kernel void SGEMV ( const int N, const float alpha, const float beta, __global float *A, __global float *x, __global float *y, __global float *y_out ) { int i = get_global_id(0); float tmp = 0.0f; for(int j = 0; j < N; j++) { tmp += alpha * A[i*N + j] * x[j]; } tmp += beta * y[i]; y_out[i] = tmp; }
こんな感じだろうか、解説すると9行目でワークアイテムの位置を取得し、それをのインデックスとする。次にベクトルのサイズ分(この場合N)だけ乗算を回す。OpenCLはカーネルに2次元配列をそのまま渡すことが出来ないため、Aのインデックスは1次元配列を2次元配列として扱ったものを使っている。
ホストプログラムを書く
カーネルプログラムが書けたら次はそれらを展開するホストプログラムを書いてやる必要がある。忘れない内にclEnqueueNDRangeKernel()を真っ先に書く。
size_t M = 1024; clEnqueuNDRangeKernel(command_queue, ko_sgemv, 1, NULL, &M, NULL, 0, NULL, NULL);
行列の列サイズを仮に1024としてる。また今回は、第6引数であるlocal_work_sizeをNULLに設定し、OpenCLランタイムにワークグループが持つワークアイテムの数の設定を任せている。
他の部分はOpenCLホストプログラミング入門の流れに沿って書いていく。
1. デバイス, コンテキスト, コマンドキューを定義する
OpenCLホストプログラミング入門と特に変更はない。
// 環境構築関係 // プラットフォームIDを確保 cl_platform_id platform_id; cl_uint platform_num; clGetPlatformIDs(1, &platform_id, &platform_num); // デバイスIDを確保 cl_device_id device_id; clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_DEFAULT, 1, &device_id, NULL); // コンテキストを作成 cl_context context; context = clCreateContext(0, 1, &device_id, NULL, NULL, NULL); // コマンドキューを作成 cl_command_queue commands; commands = clCreateCommandQueue(context, device_id, 0, NULL);
2. カーネルをビルドする
カーネルオブジェクトの変数名とclCreateKernel()の引数をsgemvに変更した。
// プログラム関係 // プログラムオブジェクトを作成 cl_program program; program = clCreateProgramWithSource(context, 1, (const char **)&kernelsource, NULL, NULL); // プログラムオブジェクトをビルド clBuildProgram(program, 0, NULL, NULL, NULL, NULL); // カーネルオブジェクトを作成 cl_kernel ko_sgemv; ko_sgemv = clCreateKernel(program, "sgemv", NULL);
3. デバイスメモリを確保する
ベクトル加算と異なり、行列ベクトル積であるのでAに関するメモリの確保の部分を追加する。
上記では行列の列サイズを1024としており、もう細かいことを考えるのが面倒なので行列サイズを1024x1024とする。
まずはホストメモリを確保する。
float h_A[1024*1024]; float h_x[1024]; float h_y[1024]; float alpha; float bata;
次に適当に初期化する。
for(int i = 0; i < 1024) { for(int j = 0; j < 1024; j++) { h_A[1024*i + j] = (float)(rand() % 100) * 0.1; } h_x[i] = (float)(rand() % 100) * 0.1; h_y[i] = (float)(rand() % 100) * 0.1; } alpha = 1; beta = 1;
デバイスメモリを確保する。d_y_outは計算結果を格納するためのメモリである。
cl_mem d_A; cl_mem d_x; cl_mem d_y; cl_mem d_y_out; d_A = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024 * 1024, h_A, NULL); d_x = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_x, NULL); d_y = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_y, NULL); d_y_out = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * 1024, NULL, NULL);
4. カーネルの引数を設定する
引数がN, , y_outと増えているので追加する。
// 引数を設定 int N = 1024; clSetKernelArg(ko_sgemv, 0, sizeof(int), &N); clSetKernelArg(ko_sgemv, 1, sizeof(float), &alpha); clSetKernelArg(ko_sgemv, 2, sizeof(float), &beta); clSetKernelArg(ko_sgemv, 3, sizeof(cl_mem), &d_A); clSetKernelArg(ko_sgemv, 4, sizeof(cl_mem), &d_x); clSetKernelArg(ko_sgemv, 5, sizeof(cl_mem), &d_y); clSetKernelArg(ko_sgemv, 6, sizeof(cl_mem), &d_y_out);
5. キューにメモリとカーネルを転送する
clEnqueueNDRangeKernel()と結果の読み出し部分に変更を加える。
// カーネルをエンキュー size_t M = 1024; clEnqueueNDRangeKernel(commands, ko_sgemv, 1, NULL, &M, NULL, 0, NULL, NULL); // 完了まで待つ clFinish(commands); // 結果を読み出し float result_y[1024]; clEnqueueReadBuffer(commands, d_y_out, CL_TRUE, 0, sizeof(float) * 1024, result_y, 0, NULL, NULL);
SGEMVのホストプログラム
以上の1~5を組み合わせたホストプログラムが以下の通り、クリーンアップと実行時間、計算結果の計測部分を追加しているが、それ以外は全く変更を加えていない。
このプログラムを適当な名前で保存し、OpenCLランタイムがインストールされている環境下でgcc -lOpenCL filename.cとするとコンパイルできる。
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <time.h> #ifdef __APPLE__ #include <OpenCL/opencl.h> #include <unistd.h> #else #include <CL/cl.h> #endif char *kernelsource = "__kernel void sgemv ( \n" \ " const int N, \n" \ " const float alpha, \n" \ " const float beta, \n" \ " __global float *A, \n" \ " __global float *x, \n" \ " __global float *y, \n" \ " __global float *y_out) { \n" \ " int i = get_global_id(0); \n" \ " float tmp = 0.0f; \n" \ " \n" \ " for(int j = 0; j < N; j++) { \n" \ " tmp += alpha * A[i*N + j] * x[j]; \n" \ " } \n" \ " tmp += beta * y[i]; \n" \ " y_out[i] = tmp; \n" \ "} \n" \ "\n"; int main(int argc, char **argv) { // 環境構築関係 // プラットフォームIDを確保 cl_platform_id platform_id; cl_uint platform_num; clGetPlatformIDs(1, &platform_id, &platform_num); // デバイスIDを確保 cl_device_id device_id; clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_DEFAULT, 1, &device_id, NULL); // コンテキストを作成 cl_context context; context = clCreateContext(0, 1, &device_id, NULL, NULL, NULL); // コマンドキューを作成 cl_command_queue commands; commands = clCreateCommandQueue(context, device_id, 0, NULL); // プログラム関係 // プログラムオブジェクトを作成 cl_program program; program = clCreateProgramWithSource(context, 1, (const char **)&kernelsource, NULL, NULL); // プログラムオブジェクトをビルド clBuildProgram(program, 0, NULL, NULL, NULL, NULL); // カーネルオブジェクトを作成 cl_kernel ko_sgemv; ko_sgemv = clCreateKernel(program, "sgemv", NULL); // メモリ関係 // ホストメモリを確保 float h_A[1024*1024]; float h_x[1024]; float h_y[1024]; float alpha; float beta; // 適当に初期化 for(int i = 0; i < 1024; i++) { for(int j = 0; j < 1024; j++) { h_A[1024*i + j] = (float)(rand() % 10) * 0.1; } h_x[i] = (float)(rand() % 10) * 0.1; h_y[i] = (float)(rand() % 10) * 0.1; } alpha = 1; beta = 1; // デバイスメモリを確保 cl_mem d_A; cl_mem d_x; cl_mem d_y; cl_mem d_y_out; d_A = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024 * 1024, h_A, NULL); d_x = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_x, NULL); d_y = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR, sizeof(float) * 1024, h_y, NULL); d_y_out = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(float) * 1024, NULL, NULL); // 計測開始 clock_t begin, end; double gpu_time, cpu_time; begin = clock(); // 実行関係 // 引数を設定 int N = 1024; clSetKernelArg(ko_sgemv, 0, sizeof(int), &N); clSetKernelArg(ko_sgemv, 1, sizeof(float), &alpha); clSetKernelArg(ko_sgemv, 2, sizeof(float), &beta); clSetKernelArg(ko_sgemv, 3, sizeof(cl_mem), &d_A); clSetKernelArg(ko_sgemv, 4, sizeof(cl_mem), &d_x); clSetKernelArg(ko_sgemv, 5, sizeof(cl_mem), &d_y); clSetKernelArg(ko_sgemv, 6, sizeof(cl_mem), &d_y_out); // カーネルをエンキュー size_t M = 1024; clEnqueueNDRangeKernel(commands, ko_sgemv, 1, NULL, &M, NULL, 0, NULL, NULL); // 完了まで待つ clFinish(commands); // 結果を読み出し float result_y[1024]; clEnqueueReadBuffer(commands, d_y_out, CL_TRUE, 0, sizeof(float) * 1024, result_y, 0, NULL, NULL); // 計測終了 end = clock(); gpu_time = (double)(end - begin) / CLOCKS_PER_SEC; // 結果を検証 float correct_y[1024]; float tmp = 0; begin = clock(); for(int i = 0; i < 1024; i++) { for(int j = 0; j < 1024; j++) { tmp += alpha * h_A[i*N + j] * h_x[j]; } tmp += beta * h_y[i]; correct_y[i] = tmp; tmp = 0; } end = clock(); cpu_time = (double)(end - begin) / CLOCKS_PER_SEC; int correct_cnt = 0; for(int i = 0; i < 1024; i++) { printf("correct_y[%d] = %f ", i, correct_y[i]); printf("result_y[%d] = %f ", i, result_y[i]); if(correct_y[i] == result_y[i]) { printf("correct !!!\n"); correct_cnt++; } else { printf("incorrect ...\n"); } } printf("%d matched.\n", correct_cnt); printf("CPU time : %lf\n", cpu_time); printf("GPU time : %lf\n", gpu_time); // クリーンアップ clReleaseMemObject(d_A); clReleaseMemObject(d_x); clReleaseMemObject(d_y); clReleaseProgram(program); clReleaseKernel(ko_sgemv); clReleaseCommandQueue(commands); clReleaseContext(context); return 0; }
ここまでの流れを正しく理解できていれば、簡単な処理に対してGPUという選択肢を考慮する事が可能になるだろう。
カーネルの最適化
カーネルに工夫を加えるとよりGPUのポテンシャルを引き出し、性能の良いプログラムを書くことが出来る。
本章ではの行列乗算を例に、どうすればより良いカーネルを書けるか解説する。なお、ここの知識はほぼHands on OpenCLの受け売りであるため、最適化に関してオススメの資料などがあれば是非教えてほしい。
最適化前のカーネル
以下は、CがサイズNxNの行列だとして、NxN個のワークアイテムを生成する事を前提にしたカーネルである。
__kernel void mmul( const int N, __global float* A, __global float* B, __global float* C ) { int i = get_global_id(0); int j = get_global_id(1); float tmp = 0.0f; for(int k = 0; k < N; k++) { tmp += A[i*N + k] * B[k * N + j]; } C[i*N + j] = tmp; }
ワークアイテムとワークグループ管理のオーバヘッド
ワークアイテムとワークグループの管理には大きなオーバーヘッドが存在する。つまり仮にN=1024だとして、NxN=1024x1024=1048576個のワークアイテムをGPUに管理させるのは得策ではない。
そこでワークアイテムを直線状に配置し、各ワークアイテムにはCの行ごとの計算をさせる。一度に計算する量が減るかもしれないが、ワークアイテムの数がNに削減できる。
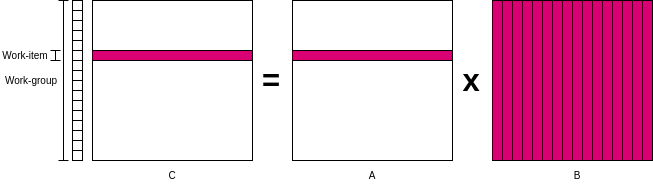
ついでに今後の最適化を見越して、clEnqueueNDRangeKernel()をいじってワークグループが持つワークアイテムの数(local_work_size)を64に設定しておく。この場合、仮にN=1024だと16個のワークグループで実行できる。
以上の最適化を加えたカーネルが以下になる。
__kernel void mmul( const N, __global float *A, __global float *B, __global float *C ) { int i = get_global_id(0); float tmp; for(int j = 0; j < N;j++) { tmp = 0.0f; for(int k = 0; k < N; k++) { tmp += A[i*N + k] * B[k*N + j]; } C[i*N + j] = tmp; } }
ただ筆者の環境ではこの最適化手法は効果が無かった。むしろ遅くなった。
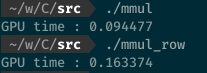
プライベートメモリの利用
前回のカーネルを引き続き最適化する。Aの行に注目してほしい、各ワークアイテムにおいてAの行を使いまわす事が出来るのは、行列乗算の計算方法からして当然だろう。このような何度も使いまわすデータはPEの近くに置いておくのが得策である。
だが、先程最適化を加えたカーネルを見てみると、引数のAに__globalが付いていることからもわかる通り、Aの値をわざわざグローバルメモリから取りに行っている。これは非常に無駄である。
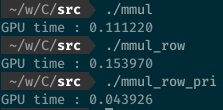
そこでAの一列分だけグローバルメモリからプライベートメモリに移してやる。その修正を加えたカーネルが以下の通り。
__kernel void mmul( const N, __global float *A, __global float *B, __global float *C ) { int i = get_global_id(0); float tmp; float Awrk[1024]; for(int j = 0; j < N; j++) { Awrk[j] = A[i*N + j]; } for(int j = 0; j < N; j++) { tmp = 0.0f; for(int k = 0; k < N; k++) { tmp += Awrk[k] * B[k*N + j]; } C[i*N + j] = tmp; } }
この最適化によって、最適化前の約3倍の計算速度を達成できた。
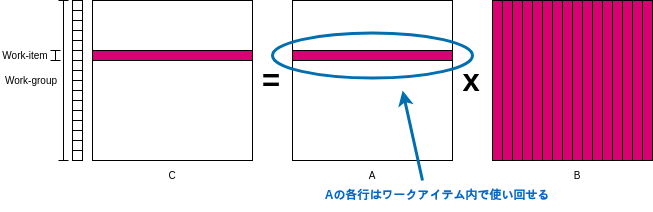
更に速く!ローカルメモリの利用
Aの行をワークアイテム内で再利用できる事は話したが、先程最適化を加えたカーネルを見てみるとBの列を取得する際に、まだグローバルメモリにアクセスしている。
これもプライベートメモリに入れてしまいたいが、カーネルの最初から最後まで不変なAの行番号と異なり、計算に用いるBの列番号はワークアイテムの一番外側のfor文で変わってしまう。
だが、内側のfor文においてBの行番号は不変であるので、ある程度Bの列も使い回せる。そこでローカルメモリにBの列を置いておき、グローバルメモリより近く、そしてワークグループ内の全てのワークアイテムがアクセス出来るようにする。
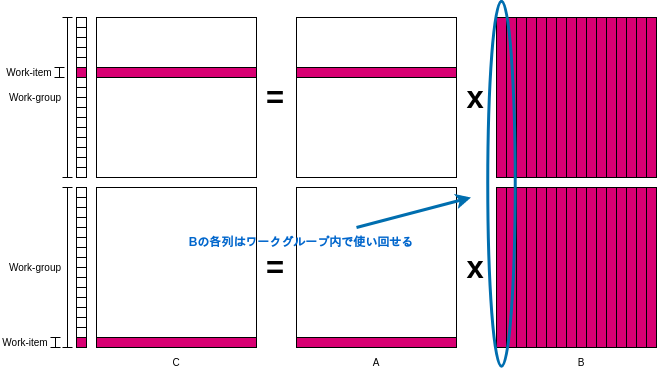
ローカルメモリを使うようにしたカーネルが以下の通り。ローカルメモリにBwrkを確保し、ワークグループ内のワークアイテム達が並行してBwrkにBの一列を格納している。
__kernel void mmul( const N, __global float *A, __global float *B, __global float *C, __local float* Bwrk ) { int i = get_global_id(0); int iloc = get_local_id(0); int nloc = get_local_size(0); float tmp; float Awrk[1024]; for(int j = 0; j < N; j++) { Awrk[j] = A[i*N + j]; } for(int j = 0; j < N; j++) { barrier(CLK_LOCAL_MEM_FENCE); for(int k = iloc; k < N; k += nloc) { Bwrk[k] = B[k*N + j]; } barrier(CLK_LOCAL_MEM_FENCE); tmp = 0.0f; for(int k = 0; k < N; k++) { tmp += Awrk[k] * Bwrk[k]; } C[i*N + j] = tmp; barrier(CLK_LOCAL_MEM_FENCE); } }
合間合間にbarrier(CLK_LOCAL_MEM_FENCE)が挿入されているが、これはバリア命令と呼び、ワークグループ内の全てのワークアイテムがこのバリア命令を実行するまで次の命令を実行させない働きがある。引数にCLK_LOCAL_MEM_FENCEを指定することでローカルメモリまでに対するアクセスが確実に完了させてから停止する。
なお大して速くならない。
真の速さを手に入れたくば
本章ではメモリ階層だけに注目して最適化を行ってきたが、実際には多くの行列乗算を高速に行うためのテクニックが存在している。
たとえば、ワークアイテムの個数は計算機のベクトル幅の倍数でなければならない。これはAMDではwavefront、NVIDIAではwarp、CPUではSIMDレーン数と呼ばれている。
データの再利用を最適化するためにはブロック化の技術が必要になる。行列をプライベートメモリにちょうど収まるようにタイルに分解したり、タイルをローカルメモリにコピーしたり、タイル間で乗算を行う技術である。
おわりに
GPUはパワーです、軽率にGPUを使ってGPUの需要を増やしましょう。次はOpenCLデバイス自作をやりたい。あと感想、意見、コメントがあれば呟くなりなんなりしてくれると泣いて喜びます。
おすすめbook
![[増補改訂]GPUを支える技術 ――超並列ハードウェアの快進撃[技術基礎] (WEB+DB PRESS plus)](https://m.media-amazon.com/images/I/51Jcf3fV-BL._SL500_.jpg "[増補改訂]GPUを支える技術 ――超並列ハードウェアの快進撃[技術基礎] (WEB+DB PRESS plus)")
おいしいケーキの作り方
この記事は、UEC Advent Caleder2021の22日目の記事です。
前回はfjdjさんのDentoo.LTの機材を組んだ話でしたね、彼のTwitterアカウントはこちらです。
こんにちは、Cra2yPierr0tです。マルチコア自作記事を載せようとしてたんですが間に合わなかったのでケーキの作り方でも書きます。食べられます。
材料
生クリームは動物性を選んでください、植物性はダメです。
- ホットケーキミックス 1袋
- 卵 5~10個
- 油 少々
- 生クリーム(動物性) 2パック
- 砂糖 必要に応じて
- その他トッピング
手順
スポンジを作る
- ホットケーキミックス、卵、油をボウルに入れる
- 任意の方法で粉っぽくなくなるまで混ぜる
- 耐熱性の型に入れ、電子レンジで600Wで15分間加熱する
- 火が通っているのを確認したら型から取り出し、包丁で三分割する
- 任意の方法で冷ます
クリームを作る
スポンジを冷ましてる間にクリームを作ります
- 生クリーム2パックをボウルに入れる
- ボウルに砂糖を好みの甘さになるまで混ぜる
- クリームが何かに塗れる硬さになるまで泡立てる
合成
スポンジとクリームが完成したら適当なトッピングを挟みつつホールケーキの形に近づけましょう。よいお年を。
明日の担当はazarasingさんの未定です。楽しみですね。
Chiselで始める爆速LSI設計
この記事は HDL Advent Calendar 2021 5日目の記事です。 qiita.com
はい、Cra2yPierr0tです。
皆さん、来週の月曜に会社や研究室に顔を出すと、ボスがニコニコしながら近づいてきて「〇〇さん、一ヶ月くらいでこんな感じのLSI作ってくれない?ツールはフリーな物を自分で探してね!」と言ってきたらどうしますか?こんな無茶振りをされるという事は、妻子を人質に取られているか拳銃を突き付けられている可能性がありますね。今この文章を読んでいる皆さん、幸運です。この記事を読めば、ボスとの交渉に使えるギリギリ成果物っぽいサムシングをこしらえる事が可能です。
ではやっていきましょう。
概要
RTLをChiselで生やしてGDSII*1をOpenLANEを使って生成しましょう。Chiselの詳しい説明はインターネットに先達が書いた記事が存在しているのでそちらを参照してください。
1. Chiselのインストール
始めにscalaのビルドツールであるsbtをインストールしましょう。インストール方法は各自OSに応じて調べてください。
$ sudo pacman -S sbt
次にChiselのプロジェクトテンプレートをダウンロード、このディレクトリ下でChiselが使えます。
$ git clone https://github.com/ucb-bar/chisel-template.git
2. Chiselを書く
今回はボスに5つの8bitの入力の分散を計算するハードウェアを要求されたと仮定しましょう。
ダウンロードしたchisel-templateのsrc/main/scala以下にvarianceディレクトリを作成し、variance.scalaにChiselを書いていきます。
.
└── chisel-template
└── src
└── main
└── scala
└── variance
└── variance.scala
以下が分散を計算するvariance.scalaの内容です。Chiselを初めて書いたので正しく動くか分かりませんが多分動きます。
import chisel3._
class variance extends Module {
val io = IO(new Bundle {
val in = Input(Vec(5, UInt(8.W)))
val out = Output(UInt((8.W)))
})
var r_sum = Reg(UInt(16.W)) // 総和
var r_sum2 = Reg(UInt(16.W)) // 2乗の総和
val r_average_2 = Reg(UInt(16.W)) // 平均の2乗
val r_average2 = Reg(UInt(16.W)) // 2乗の平均
r_sum = 0.U
r_sum2 = 0.U
for (i <- 0 to 4) {
r_sum = r_sum + io.in(i)
r_sum2 = r_sum2 + io.in(i) * io.in(i)
}
r_average_2 := (r_sum / 5.U) * (r_sum / 5.U)
r_average2 := r_sum2 / 5.U
io.out := r_average2 - r_average_2
}
object Elaborate extends App {
chisel3.Driver.execute(args, () => new variance)
}
そしたらchisel-template直下でsbt "run"を実行すればvariance.vが生成されます。
$ sbt "run"
variance.vは一旦置いておき、次はOpenLANEの準備に入ります。
3. OpenLANEのインストール
先程生成したTop.vをGDSIIにするために、OpenLANEをインストールしましょう。 OpenLANEは約20個のOSSを組み合わせて作成されたRTL-to-GDSIIコンパイラです。すごいね。
まずはOpenLANEリポジトリをクローン
$ git clone git@github.com:The-OpenROAD-Project/OpenLane.git $ cd OpenLane
次にOpenLANEのDockerコンテナをダウンロード。事前にDockerデーモンを起動しておきましょう。
$ make pull-openlane
最後にskywater PDKをビルド、20分くらい掛かります。
$ make pdk
次は遂にGDSIIの生成です。
4. OpenLANEでGDSIIを生成
OpenLaneディレクトリ直下で以下のコマンドを実行し、designs以下に自分のデザインのディレクトリとコンフィグを追加しましょう。
$ make mount
bash-4.2$ ./flow.tcl -design variance -init_design_config
するとOpenLane/designs以下にvarianceディレクトリが生成されます。そしたらvariance/srcに先程生成したvariance.vを追加しましょう。
$ cp ../chisel-template/variance.v designs/variance/src
次にvarianceディレクトリにあるconfig.tclを編集します。CLOCK_PERIODとCLOCK_PORTの値を編集するだけで大丈夫です。
# User config set ::env(DESIGN_NAME) variance # Change if needed set ::env(VERILOG_FILES) [glob $::env(DESIGN_DIR)/src/*.v] # Fill this # 10MHz set ::env(CLOCK_PERIOD) "100.0" set ::env(CLOCK_PORT) "clock" set filename $::env(DESIGN_DIR)/$::env(PDK)_$::env(STD_CELL_LIBRARY)_config.tcl if { [file exists $filename] == 1} { source $filename }
各変数の説明はここに書いてあります Variables information - OpenLane Documentation
config.tclの編集が終わったら、OpenLaneディレクトリ直下で以下のコマンドを実行してビルドを開始します。祈りましょう。
$ make mount $ ./flow.tcl -design variance
ビルドが完了したらOpenLane/designs/variance/runs/RUN_<実行時刻>/result/finishingにvariance.gdsが生成されています。
 klayoutでレイアウトを見ることが出来ます、これをボスに見せて猶予を貰いましょう。
klayoutでレイアウトを見ることが出来ます、これをボスに見せて猶予を貰いましょう。
おわりに
という訳でChiselからGDSIIを生成しました。実際にChisekを書き始めてからGDSIIファイルが生成されるまで大体3時間です。早いですね。 もし実際にOpenLANEを用いてオレオレLSIを焼きたいなら、OpenMPW Shuttle Programがオススメです。
GoogleがEfablessに出資したおかげで、デザインをオープンにする代わりに無料でLSIを焼くことが出来ます。送料も無料で5個の評価ボードと50個のチップがあなたの家に届きます!
流石にこの記事よりは時間も必要になりますしconfig.tclもそこそこ書くことになりますが、自分でチップを焼くことは他の現代人に対し圧倒的なアドバンテージになります。そんな事を言っていいのか、俺は130nmプロセスを焼いた漢だぞ。
もし興味が湧いたり質問がありましたらVLSI.jpを参照するかMake:LSIを覗いてみるか筆者に聞いてみてください。良き半導体ライフを。
参考
AviUtlで棒読みちゃんの音質が変わる話
オチは無いし疑問で終わります。
棒読みちゃんから出力された音声ファイルは音質がよろしくありません。これはサンプリングレートは8000Hzなので仕方がないでしょう。
これをプラグイン無しのAviUtlに突っ込んで44100Hzで出力するとやたら鮮明になります。不思議ですね。
これをAviUtlに頼らずやっていきたい。そこでAudacityで44100Hzで出力させます。するとこちら、
カスですね。一体何が違うのか、スペクトルを比較してみましょう。
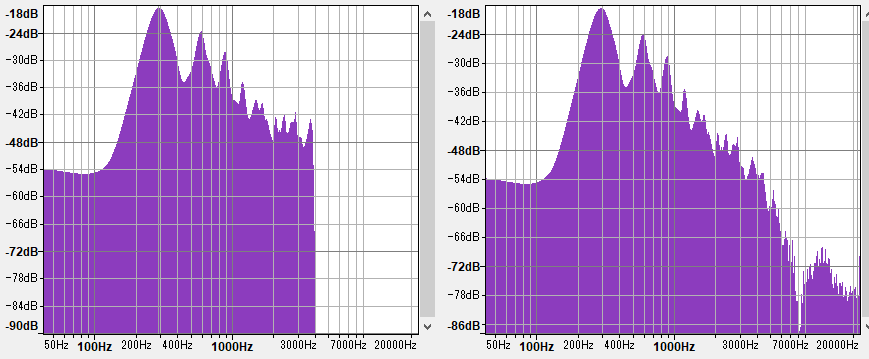
Audacityだと4000Hz以降ぶっつり切れてますがAviUtlだと存在していますね。ローパスフィルタを使ってAviUtlの出力の4000Hz以降をカットすると、Audacityと似たような音質になります。よって4000Hz以降を如何に補間するかが重要だと推測できます。
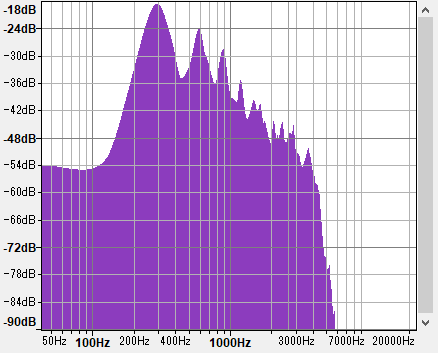
すべての音声データはffmpegに通じているので、棒読みちゃん出力をffmpegで44100Hzに変換してみましょう。
若干マシになりましたね。スペクトルを比較してみましょう。
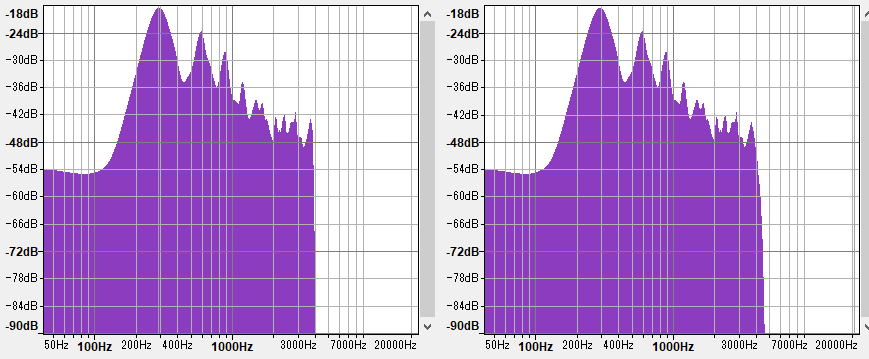
ffmpeg出力には4000Hz以降が僅かですが補間されています、俺には見えるんだ。 というわけで筋はいいですがffmpegでもなさそう。
AviUtlどうなってんだ、ffmpegより強力な補間技術を持っている?それともコーデック周りとかで僕が知らない常識が存在しているのか、誰か教えてくれ。
自宅で簡単☆計算加速装置
この記事は UEC Advent Calender2020 10日目の記事です。前日の記事はSuzukeさんのクソコラ拡張機能の作り方でしたね。
アクセラレータと聞いて白髪のロリコンが最初に思い浮かぶオタクのみなさん、作りましょう。
本記事では何か適当なアクセラレータを自作し、某ラノベを読んで拗らせたオタクに「俺はアクセラレータ自作したけど、お前は?」と煽り散らす事を目的としています。
下調べ
まずは世の中にはどんなアクセラレータが存在するのか見てみましょう。
Coral USB Accelerator
www.switch-science.com Coral社が販売しているAIアクセラレータ、googleのEdge TPUが乗っています。 Type-Cで接続するだけで推論が加速する!嬉しい!
Nural Compute Stick 2
www.switch-science.com intelが販売しているDNN用アクセラレータ、見た目がすき。
K210
www.switch-science.com 正確にはアクセラレータではない、RISC-VデュアルコアでセキュリティやAI、音声認識向けのアクセラレータがもりもり乗ったSoC。お化け。
要はアクセラレータとはオンチップ or 外付けで特定の計算が爆速になる不思議な半導体のことを指しているわけです。今回は行列計算関係のアクセラレータを作りましょう。流行ってるので。
コア技術
如何にしてCPUの逐次処理より高効率に行列計算を行うか?答えはシストリックアレイです。シストリックアレイとは単純な処理を行うPE(Processing Element)と呼ばれる演算器を直線状、格子状、ツリー状等に並べることで、高い並列性で特定の演算(高速フーリエ変換、ソート、行列演算 etc..)を実行できるアーキテクチャを指しています。
今回用いるPEは左と上のポートから来た値を乗算し、バッファに加算、また右の値を左のポートに出力する単純な処理を行います。
このPEを線形に並べることで行列-ベクトル積を実行できるシストリックアレイが完成します。
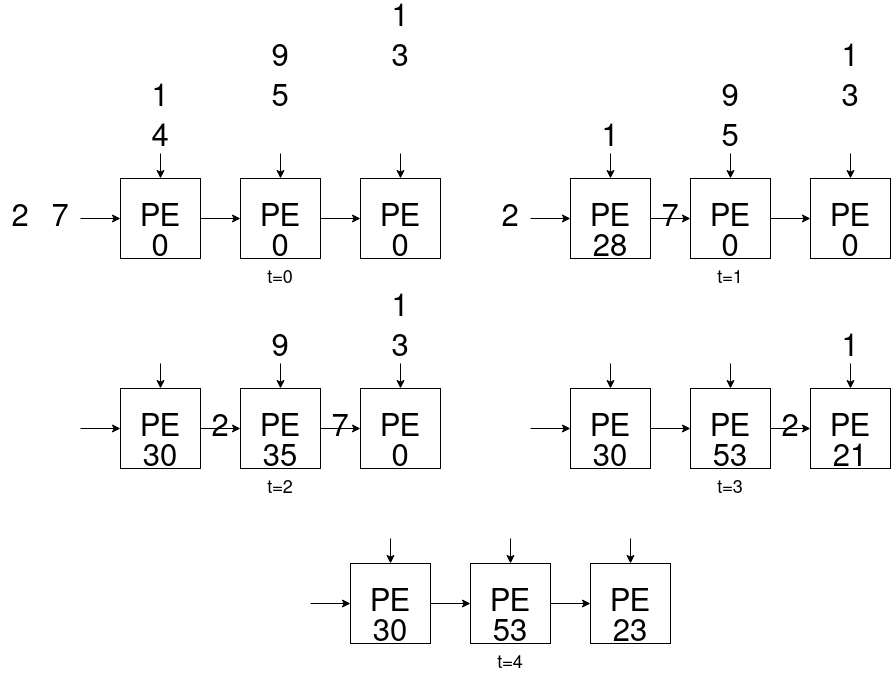
for(int i = 0; i < N; i++){ for(int j = 0; j < N; i++){ C[i] += A[i][j]*B[j]; } }
の通りO(N2)ですが、シストリックアレイを用いると行列サイズNに対して2N-1ステップで計算が完了するため効率的です。本記事ではこのシストリックアレイをコアに据え、行列-ベクトル積のアクセラレータを作成します。
悲しみ
行列-ベクトル積のアクセラレータを作成します。と意気込んだものの障害は多いです。
1. CPU-アクセラレータ間の通信
アクセラレータとCPUでデータを受送信する上でDMAを使えたら嬉しいですね(早いので)?DMAが使えるFPGAの値段を見てみましょう!
www.intel.co.jp 12万円 www.avnet.com 20万円 www.digikey.jp 32万円
これは草。学生風情が趣味で買うものでは無いのは明らかです。Zynq?知らない子ですね。つまり我々はMAX1000だとかCYC1000だとか、DE0-CVだとかの低価格帯ボードで出来るだけ高速に外部のCPUと通信させる必要があるわけですね。
2. CPUの強さ
アクセラレータを作るからにはCPUより高速に演算が出来なければアクセラレータとは呼べません。一般的なデスクトップやノートのCPUに対してのアクセラレータを作るのは上記の成約から明らかに無謀です。上記の低価格帯ボードでも計算をアクセラレート出来る程度に弱いマイコンに対してのアクセラレータにするべきです。ちなみにラズパイzeroには勝てません、あれ1000円の癖に1GHzで動いてます、こちらのFPGAは早くて100MHz、無謀ですね。
方針
何に対してのアクセラレータにするか、今回は上記の障害よりNucleo-f303k8に接続することを前提にします。
Nucleo-f303k8のCortex-M4Fは動作周波数が72MHz!手元のFPGAは早くて50MHz!ギリギリ希望が見えますね(みえない)。また通信方式はSPI(Serial Peripheral Interface)を採用します(50MHzで通信出来るらしい)。
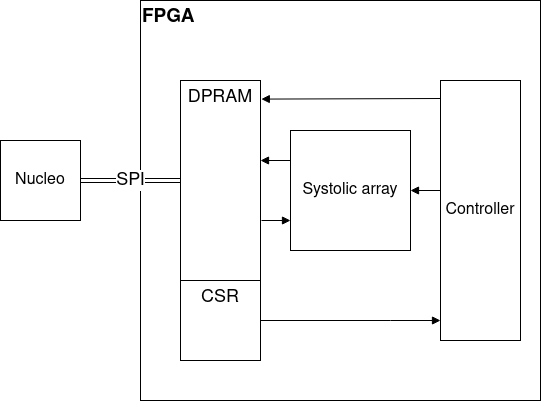
つまり最終的な外観は以下になります。

では次にアクセラレータの構成を決定しましょう。シストリックアレイをコアに、周囲には行列データ格納用のRAM、行列サイズ格納用のCSR、それら全てを制御するコントローラとするのが妥当な構成ですね。
実装
SystemVerilogで殴って!終わり!
で終わらせるのは流石に手抜きなのでPEのRTLだけ解説します。
module PE #( parameter WORD_SIZE = 16 )( input logic clk, input logic read, input logic reset, input logic [WORD_SIZE-1:0] l_d_i, input logic [WORD_SIZE-1:0] r_d_i, input logic [WORD_SIZE-1:0] t_d_i, output logic [WORD_SIZE-1:0] l_d_o, output logic [WORD_SIZE-1:0] r_d_o ); logic [WORD_SIZE-1:0] buffer_w; logic [WORD_SIZE-1:0] buffer; logic [WORD_SIZE-1:0] r_d_o_r; always_comb begin if(reset) begin buffer_w = '0; end else if(read) begin buffer_w = r_d_i; end else begin buffer_w = buffer + l_d_i * t_d_i; end r_d_o = r_d_o_r; if(read) begin l_d_o = buffer; end else begin l_d_o = '0; end end always_ff @(posedge clk) begin buffer <= buffer_w; r_d_o_r <= l_d_i; end endmodule
入出力のl_d_iは左からのデータ入力、t_d_iは上からのデータ入力、r_d_oは右へのデータ出力で、これらは前掲したPEの図に載っています。l_d_o、r_d_iは行列-ベクトル積を計算した結果を左側から出力するための線であり、入力のreadがHighになるとこれらの線は使われます。read、resetが0の場合、左と上から入力を掛け算し内部バッファの値と加算した値をbuffer_wに入力し、クロックの立ち上がりでbufferの値が更新されます。また同時に右へ入力する値を格納するバッファr_d_o_rの値も更新されます。
性能
SPIの通信速度は10MHzまでは安定に動作します。明らかにアクセラレータとしての性能を満たせませんね。かなしいね、知ってた。
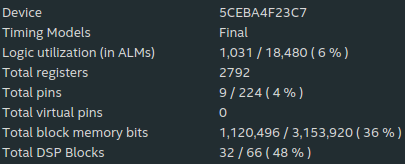
合成結果は以下の画像の通りです。
というか32x32以上のサイズで計算させるとバグるので世界終わってほしい。
テストベンチはこちら、mbed便利ですね
#include "mbed.h" SPI spi(A6, A5, A4); DigitalOut cs(A3); Serial pc(USBTX, USBRX); Timer tm; int main(){ cs = 1; spi.format(16, 0); spi.frequency(1000000); unsigned int A[31][31], B[31], C_1[31], C_2[31]; for(int i = 0; i < t; i++){ for(int j = 0; j < t; j++){ A[i][j] = j; } B[i] = i; } // ---- run on accelerator ---- cs = 0; tm.start(); spi.write(0x1001); // write vector size spi.write(0x001f); // size 31 spi.write(0x1002); // write matrix column size spi.write(0x001f); // size 31 spi.write(0x4000); // start input vector data for(int i = 0; i < 31; i++){ spi.write(B[i]); } spi.write(0x5000); // start input matrix data for(int i = 0; i < 31; i++){ for(int j = 0; j < 31; j++){ spi.write(A[j][i]); } } spi.write(0x3000); // start calculation spi.write(0x6000); // read result for(int i = 0; i < 31; i++){ C_1[i] = spi.write(0x0000); } tm.stop(); cs = 1; printf("The time taken was %d us\n\r", tm.read_us()); printf("The time taken was %d ms\n\r", tm.read_ms()); for(int i = 0; i < 31; i++){ printf("C_1[%d] = 0x%04x\n\r", i, C_1[i]); } tm.reset(); // ---- run on cpu ---- tm.start(); for(int i = 0; i < 31; i++){ C_2[i] = 0; } for(int i = 0; i < 31; i++){ for(int j = 0; j < 31; j++){ C_2[i] += A[i][j] * B[j]; } } tm.stop(); printf("The time taken was %d us\n\r", tm.read_us()); printf("The time taken was %d ms\n\r", tm.read_ms()); for(int i = 0; i < 31; i++){ printf("C_2[%d] = 0x%04x\n\r", i, C_2[i]); } }
適当に31x31行列の計算をさせた結果がこちら

マイコンのCPUで同じ計算をさせた結果がこちら
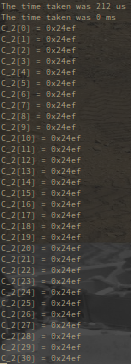
なんと0.01倍も高速化しました!おやすみなさい
参考文献

- 発売日: 2016/04/22
- メディア: 単行本(ソフトカバー)
自作CPU Any% RTA 2:28:17.13
自作CPU Any% RTA
夏休みが9/30に終わるCra2yPierr0tです、こんばんは。タイトル通りです、始めましょう。いや間違えた、はーじまーるよー
speedrun.comを確認しましたが、なぜか自作CPU RTAを走ってる人がいなかったので、今回は私がレギュレーションを決めたいと思います。
ISAを考え始めるところからスタートで、FPGAボードに載ってるLEDで1~10の総和が計算出来てる事が確認できた時点でタイマーストップ 、ということでどうでしょうか。
レギュレーション
ISA検討から自作CPUで1~10の総和を計算まで、確認はオンボードLED
チャート
ところで今回走るチャートの説明がまだでしたね。
- ISA策定
- アーキテクチャ策定
- レジスタ作成
- デコーダ作成
- コントローラ作成
- ALU作成
- RAM作成
- Quartusプロジェクト作成
- CPU作成
- ROM作成
- CPU, RAM, ROM結合
- プログラミング(バイナリ書く方)
- ピンアサイン
- 合成
- プログラミング(FPGAに書き込む方)
以上です、時刻は23時くらい、タイマースタート
経過
経過を写真と説明で報告します
1. ISA策定
大体6分でISAを決定しました。

2. アーキテクチャ策定
約1分でマイクロアーキテクチャを決めました。
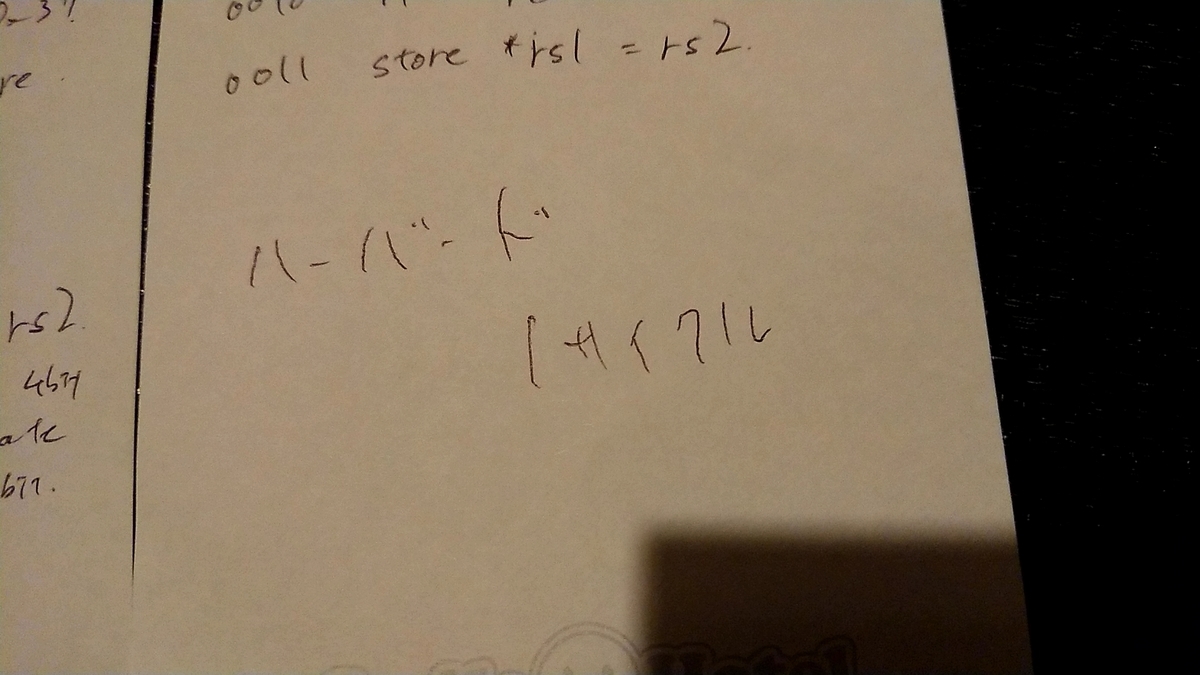
3. レジスタ作成
大体5分で書きました。
module regfile( input logic clk, input logic [3:0] a_rs1, input logic [3:0] a_rs2, input logic [3:0] a_rd, input logic [15:0] d_rd, input logic we_rd, output logic [15:0] d_rs1, output logic [15:0] d_rs2 ); logic [15:0] mem[0:15]; assign d_rs1 = mem[a_rs1]; assign d_rs2 = mem[a_rs2]; always_ff @(posedge clk) begin if(we_rd) begin mem[a_rd] = d_rd; end end endmodule
特にトリッキーな事はやってないですね。読み出しは組み合わせ回路になっていて、we_rdがhighの場合書き込みが出来る。因みに今後出てくるRTL記述の不可解な点や非効率的な点等は全て死ぬほど焦っている事によるものだと解釈して下さい。
4. デコーダ作成
脳がバグってるのか手がバグってるのか知りませんがデコーダの作成に約6分掛かっています。
module decoder( input logic [15:0] instr, output logic [3:0] opcode, output logic [3:0] a_rs1, output logic [3:0] a_rs2, output logic [3:0] a_rd, output logic [7:0] immediate ); assign opcode = instr[15:12]; assign a_rd = instr[11:8]; assign a_rs1 = instr[7:4]; assign a_rs2 = instr[3:0]; assign immediate = instr[7:0]; endmodule
instrを各フィールド毎にバラすだけの組み合わせ回路ですね、これをデコーダと呼んでいいのかは非常に怪しいですがまあいいでしょう。
5. コントローラ作成
約3分で書きました
module controller( input logic [3:0] opcode, output logic we_ram, output logic we_rd ); assign we_ram = (opcode == 4'b0011) ? 1'b1 : 1'b0; assign we_rd = (opcode == 4'b0000) ? 1'b1 : (opcode == 4'b0001) ? 1'b1 : (opcode == 4'b0010) ? 1'b1 : 1'b0; endmodule
入力のopcodeの値に応じて、レジスタに書き込む命令ならwe_rdをhighに、ramに書き込む命令ならwe_ramをhighに、それ以外ならlowにする組み合わせ回路ですね。魅せポイントは3項間演算子です。許して。
6. ALU作成
これも大体3分で書きました
module ALU( input logic [3:0] opcode, input logic [15:0] d_rs1, input logic [15:0] d_rs2, input logic [7:0] immediate, output logic [15:0] d_rd ); always_comb begin case(opcode) 4'b0000: d_rd = d_rs1 + d_rs2; 4'b0001: d_rd = d_rs1; 4'b0010: d_rd = {8'h00, immediate}; default: d_rd = 16'h0000; endcase end endmodule
入力のopcodeの値に応じてd_rdに入力する値を変える組み合わせ回路ですね。immediateのスペルが間違ってなくてえらい。ここらへんで1~10の総和を計算するのにload命令をmov命令は要らない事に気が付きました。
7. RAM作成
約3分使いました。今回のレギュレーションだと正直RAMは要らないんですが(そもそもload命令を実装してない)、RAMが無いCPUとか笑えるので渋々書きました。RTAやぞ
module RAM( input logic clk, input logic [15:0] d_rs1, input logic [15:0] d_rs2, input logic we_ram ); logic [15:0] mem[0:1024]; always_ff @(posedge clk) begin if(we_ram) begin mem[d_rs1] = d_rs2; end end endmodule
we_ramがhighの場合にd_rs1の値をアドレスにしてd_rs2の値をストアする仕組みですね。
8. Quartusのプロジェクト作成
Quartusの起動とプロジェクト作成に若干手間取って9分使いました。初心者かな? 手元にあるMAX1000を対象にしています。
9. CPU作成
やることはレジスタとデコーダとALUとコントローラをまとめるだけです、9分。
module rta_cpu( input logic clk, input logic [15:0] instr, output logic we_ram, output logic [15:0] d_rs1, output logic [15:0] d_rs2, output logic [7:0] pc = 8'h00 ); logic [3:0] opcode; logic [3:0] a_rs1; logic [3:0] a_rs2; logic [3:0] a_rd; logic [7:0] immediate; logic [15:0] d_rd; logic we_rd; always_ff @(posedge clk) begin if(pc != 8'h30) begin pc <= pc + 8'h1; end else begin pc <= pc; end end decoder deocoder( .instr(instr), .opcode(opcode), .a_rs1(a_rs1), .a_rs2(a_rs2), .a_rd(a_rd), .immediate(immediate) ); controller controller( .opcode(opcode), .we_ram(we_ram), .we_rd(we_rd) ); ALU ALU( .opcode(opcode), .d_rs1(d_rs1), .d_rs2(d_rs2), .immediate(immediate), .d_rd(d_rd) ); regfile regfile( .clk(clk), .a_rs1(a_rs1), .a_rs2(a_rs2), .a_rd(a_rd), .d_rd(d_rd), .we_rd(we_rd), .d_rs1(d_rs1), .d_rs2(d_rs2) ); endmodule
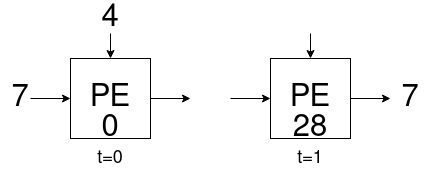
書き始めたあたりでチャートにプログラムカウンタ(PC)の作成を組み込んでなかった事に気が付きました。再走しろ。とりあえずアドレスが0x30になったあたりで停止するようにしました。分岐命令が無いのでループで停止が作れない。仕方ないね。
10. ROM作成
Quartusではinital文でメモリの初期化をしてくれないのでROMのIPを生成します。Vivadoを見習え。1分。
11. CPU, RAM, ROM結合
ここでLED出力のMMIOのアドレスを決めていなかった事に気が付きました。やる気あんのか。とりあえず0xFFにストアすると書き込んだ値がLEDに出力されるようにした。3.5分掛かった。
module rta_computer( input logic clk, output logic [7:0] led = 8'h00 ); logic [15:0] instr; logic [15:0] d_rs1; logic [15:0] d_rs2; logic [15:0] pc; logic we_ram; rta_cpu rta_cpu( .clk(clk), .instr(instr), .we_ram(we_ram), .d_rs1(d_rs1), .d_rs2(d_rs2), .pc(pc) ); always_ff @(clk) begin if(we_ram && (d_rs1 == 16'hff)) begin led <= d_rs2; end else begin led <= led; end end RAM RAM( .clk(clk), .d_rs1(d_rs1), .d_rs2(d_rs2), .we_ram(we_ram) ); rom rom( .address(pc), .clock(clk), .q(instr) ); endmodule
12. プログラミング(バイナリ書く方)
なぐり書きして人力アセンブル、勢いがあっていいですね。

mifファイルに書き込んでIPのROMに読み込ませます。4分位掛かった気がする。
13. ピンアサイン
MAX1000のマニュアルを読んでPin Plannerポチポチ、1分。
14. 合成
一回の合成に54秒掛かりました。
15. プログラミング(FPGAに書き込む方)
合成が完了し、わくわくしながらFPGAに書き込み!

眩しい!!!!
え????なんで???1から10の総和って0xFFなの?????
デバッグ
なんでや
 シミュレーターだと正常に動いとるやん
シミュレーターだと正常に動いとるやん
デバッグ
ここらへんで日付が変わる、様々頑張る
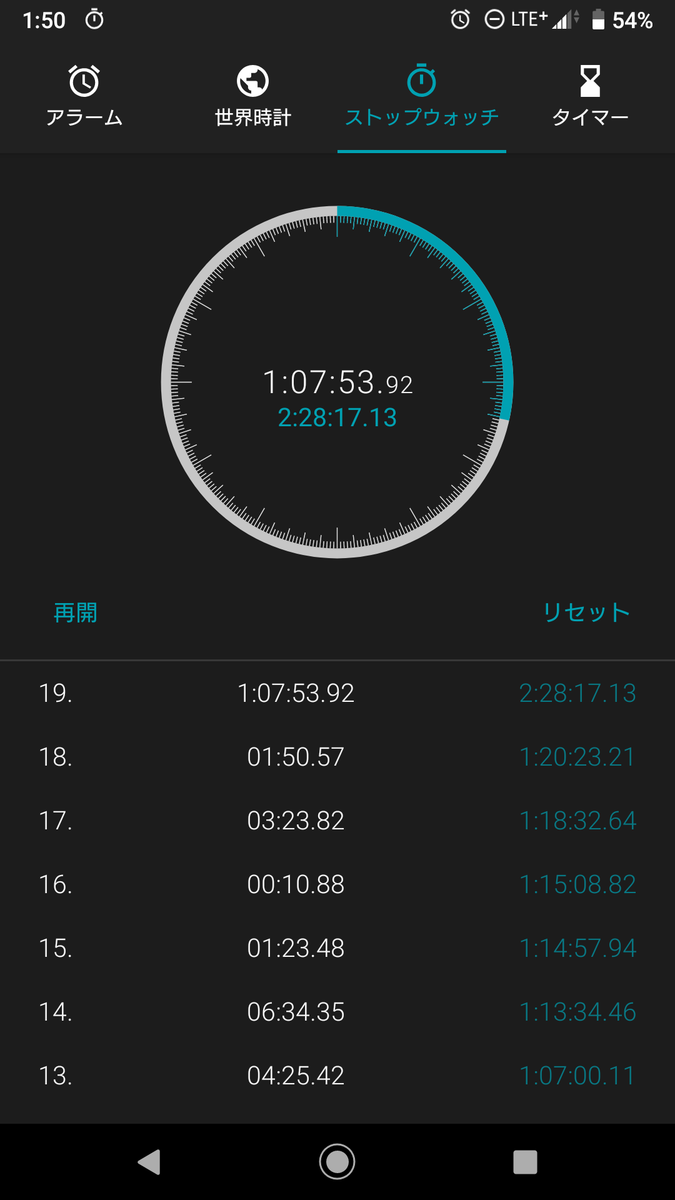
デバッグ
1時間07分53秒後....
確認
動いた。なんでや、原因全く判明してへんぞ。
 ご覧下さい、LEDが00110111と光ってますね、これは10進数で55です。計算出来ていますね。嬉しいですね。嬉しい!!!!
ご覧下さい、LEDが00110111と光ってますね、これは10進数で55です。計算出来ていますね。嬉しいですね。嬉しい!!!!
結果
結果は2時間28分17秒13でした。デバッグに1時間割いたうえに原因不明のまま動いたのが酷いですね。最早RTAと言うべきなのか怪しいレベル。いや言うべきではないでしょうね。まあええ、動けばばええんや。(朝1:30)
感想
完走した感想ですがガバガバレギュレーションにガバガバチャート、酷いものですが完動して感動しました。これもう僕が自作CPU RTA世界王者自称していいですよね。世界最速は2:28:17.13で暫定一位です。
一体何処に急いでCPUを作る需要があるのか知りませんが、レギュレーションはもう少し詰めたら楽しめそうです。じゃああなたも走りましょう、
僕も走ったんだからさ。
勧誘
ところで自作CPU研究会はいつでも参加者を募集してます。入りたい方は手段は問わないので僕を含むメンバーの誰かに参加希望の旨を伝えて下さい。
失礼しました。